 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Analysis of Bilingual and Trilingual Wav2Vec Models for Automatic Speech Recognition in Multilingual Oral History Archives
Jul 24, 2024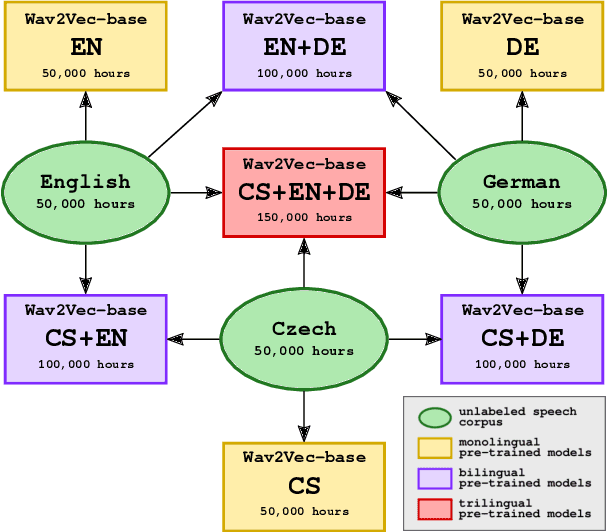
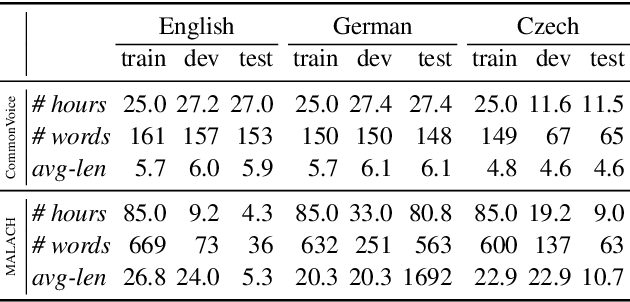
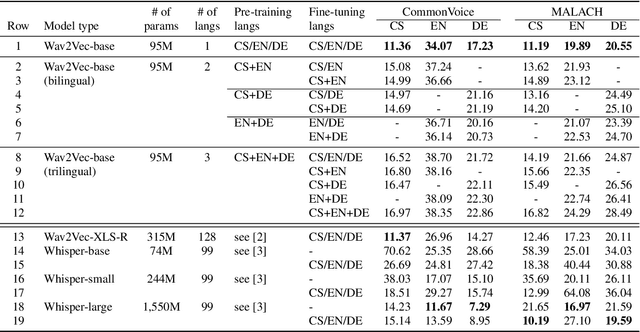
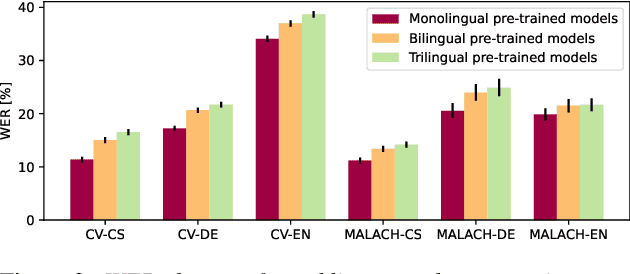
In this paper, we are comparing monolingual Wav2Vec 2.0 models with various multilingual models to see whether we could improve speech recognition performance on a unique oral history archive containing a lot of mixed-language sentences. Our main goal is to push forward research on this unique dataset, which is an extremely valuable part of our cultural heritage. Our results suggest that monolingual speech recognition models are, in most cases, superior to multilingual models, even when processing the oral history archive full of mixed-language sentences from non-native speakers. We also performed the same experiments on the public CommonVoice dataset to verify our results. We are contributing to the research community by releasing our pre-trained models to the public.
Transformer-based encoder-encoder architecture for Spoken Term Detection
Nov 02, 2022


The paper presents a method for spoken term detection based on the Transformer architecture. We propose the encoder-encoder architecture employing two BERT-like encoders with additional modifications, including convolutional and upsampling layers, attention masking, and shared parameters. The encoders project a recognized hypothesis and a searched term into a shared embedding space, where the score of the putative hit is computed using the calibrated dot product. In the experiments, we used the Wav2Vec 2.0 speech recognizer, and the proposed system outperformed a baseline method based on deep LSTMs on the English and Czech STD datasets based on USC Shoah Foundation Visual History Archive (MALACH).