 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Analysis of Bilingual and Trilingual Wav2Vec Models for Automatic Speech Recognition in Multilingual Oral History Archives
Jul 24, 2024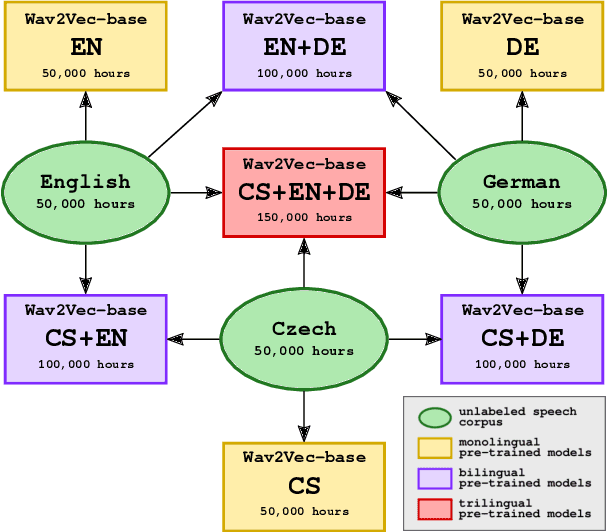
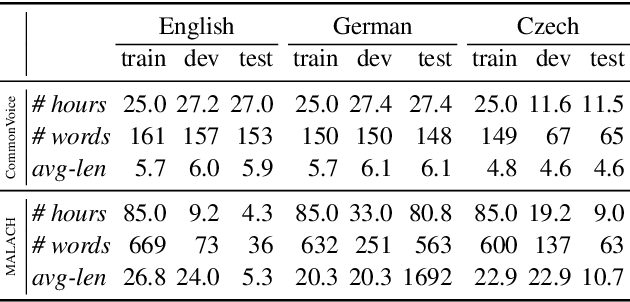
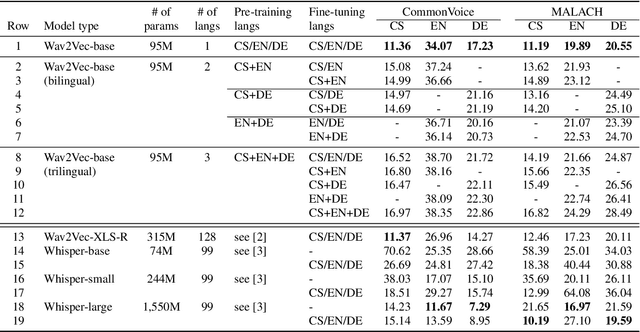
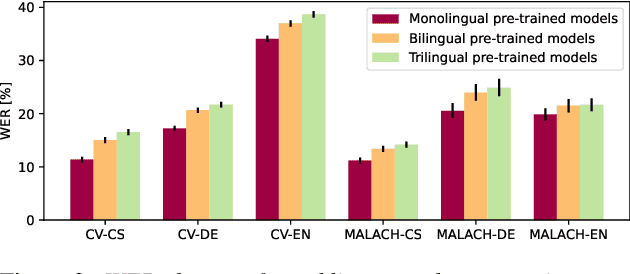
In this paper, we are comparing monolingual Wav2Vec 2.0 models with various multilingual models to see whether we could improve speech recognition performance on a unique oral history archive containing a lot of mixed-language sentences. Our main goal is to push forward research on this unique dataset, which is an extremely valuable part of our cultural heritage. Our results suggest that monolingual speech recognition models are, in most cases, superior to multilingual models, even when processing the oral history archive full of mixed-language sentences from non-native speakers. We also performed the same experiments on the public CommonVoice dataset to verify our results. We are contributing to the research community by releasing our pre-trained models to the public.
Zero-Shot vs. Few-Shot Multi-Speaker TTS Using Pre-trained Czech SpeechT5 Model
Jul 24, 2024In this paper, we experimented with the SpeechT5 model pre-trained on large-scale datasets. We pre-trained the foundation model from scratch and fine-tuned it on a large-scale robust multi-speaker text-to-speech (TTS) task. We tested the model capabilities in a zero- and few-shot scenario. Based on two listening tests, we evaluated the synthetic audio quality and the similarity of how synthetic voices resemble real voices. Our results showed that the SpeechT5 model can generate a synthetic voice for any speaker using only one minute of the target speaker's data. We successfully demonstrated the high quality and similarity of our synthetic voices on publicly known Czech politicians and celebrities.
Speech Technology Services for Oral History Research
Apr 26, 2024


Oral history is about oral sources of witnesses and commentors on historical events. Speech technology is an important instrument to process such recordings in order to obtain transcription and further enhancements to structure the oral account In this contribution we address the transcription portal and the webservices associated with speech processing at BAS, speech solutions developed at LINDAT, how to do it yourself with Whisper, remaining challenges, and future developments.
Transfer Learning of Transformer-based Speech Recognition Models from Czech to Slovak
Jun 07, 2023In this paper, we are comparing several methods of training the Slovak speech recognition models based on the Transformers architecture. Specifically, we are exploring the approach of transfer learning from the existing Czech pre-trained Wav2Vec 2.0 model into Slovak. We are demonstrating the benefits of the proposed approach on three Slovak datasets. Our Slovak models scored the best results when initializing the weights from the Czech model at the beginning of the pre-training phase. Our results show that the knowledge stored in the Cezch pre-trained model can be successfully reused to solve tasks in Slovak while outperforming even much larger public multilingual models.
Transformer-based encoder-encoder architecture for Spoken Term Detection
Nov 02, 2022


The paper presents a method for spoken term detection based on the Transformer architecture. We propose the encoder-encoder architecture employing two BERT-like encoders with additional modifications, including convolutional and upsampling layers, attention masking, and shared parameters. The encoders project a recognized hypothesis and a searched term into a shared embedding space, where the score of the putative hit is computed using the calibrated dot product. In the experiments, we used the Wav2Vec 2.0 speech recognizer, and the proposed system outperformed a baseline method based on deep LSTMs on the English and Czech STD datasets based on USC Shoah Foundation Visual History Archive (MALACH).
Transformer-based Automatic Speech Recognition of Formal and Colloquial Czech in MALACH Project
Jun 15, 2022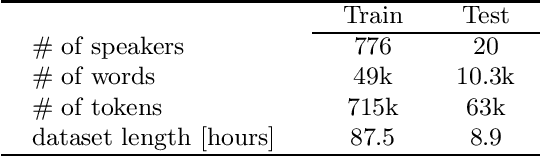
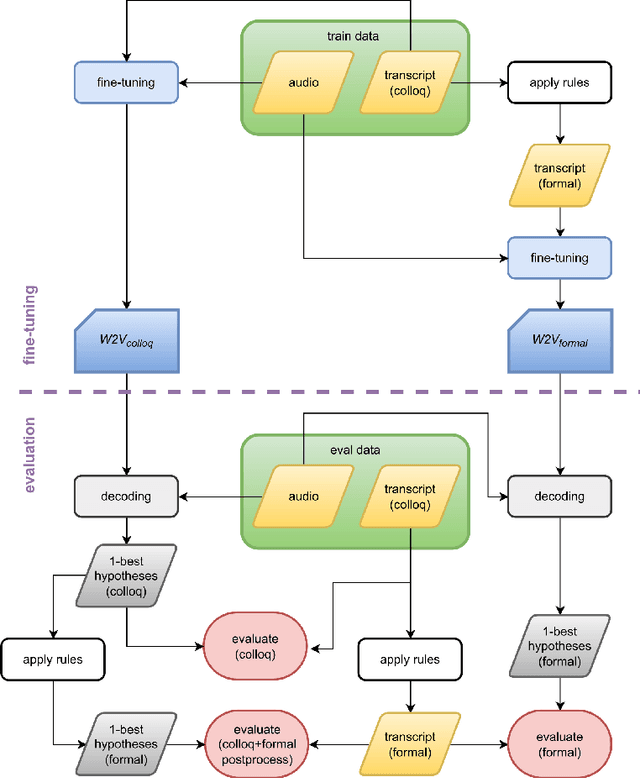

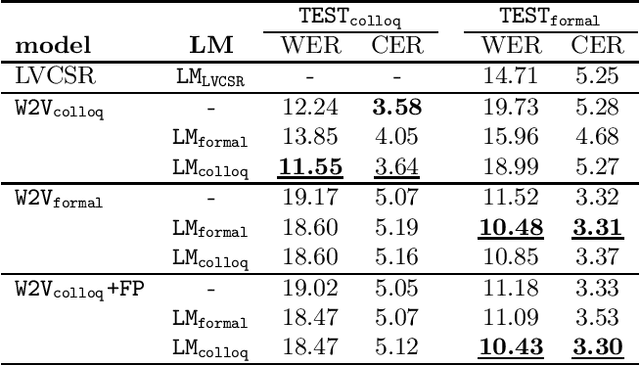
Czech is a very specific language due to its large differences between the formal and the colloquial form of speech. While the formal (written) form is used mainly in official documents, literature, and public speeches, the colloquial (spoken) form is used widely among people in casual speeches. This gap introduces serious problems for ASR systems, especially when training or evaluating ASR models on datasets containing a lot of colloquial speech, such as the MALACH project. In this paper, we are addressing this problem in the light of a new paradigm in end-to-end ASR systems -- recently introduced self-supervised audio Transformers. Specifically, we are investigating the influence of colloquial speech on the performance of Wav2Vec 2.0 models and their ability to transcribe colloquial speech directly into formal transcripts. We are presenting results with both formal and colloquial forms in the training transcripts, language models, and evaluation transcripts.
Exploring Capabilities of Monolingual Audio Transformers using Large Datasets in Automatic Speech Recognition of Czech
Jun 15, 2022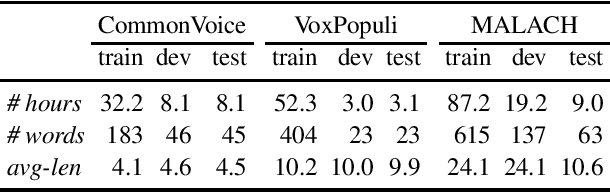



In this paper, we present our progress in pretraining Czech monolingual audio transformers from a large dataset containing more than 80 thousand hours of unlabeled speech, and subsequently fine-tuning the model on automatic speech recognition tasks using a combination of in-domain data and almost 6 thousand hours of out-of-domain transcribed speech. We are presenting a large palette of experiments with various fine-tuning setups evaluated on two public datasets (CommonVoice and VoxPopuli) and one extremely challenging dataset from the MALACH project. Our results show that monolingual Wav2Vec 2.0 models are robust ASR systems, which can take advantage of large labeled and unlabeled datasets and successfully compete with state-of-the-art LVCSR systems. Moreover, Wav2Vec models proved to be good zero-shot learners when no training data are available for the target ASR task.
Comparison of Czech Transformers on Text Classification Tasks
Jul 21, 2021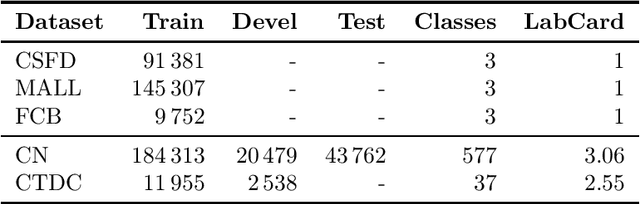
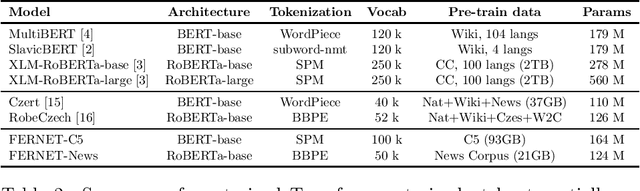
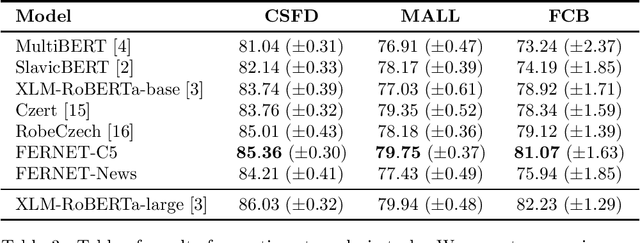
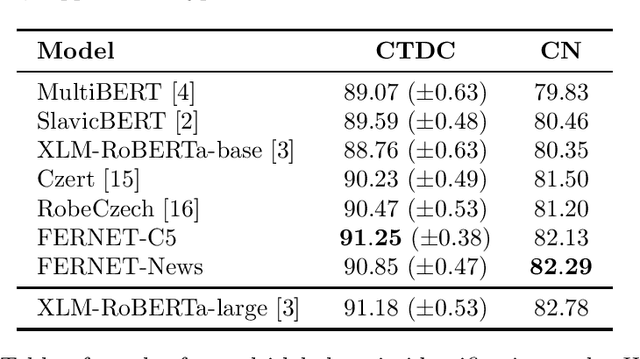
In this paper, we present our progress in pre-training monolingual Transformers for Czech and contribute to the research community by releasing our models for public. The need for such models emerged from our effort to employ Transformers in our language-specific tasks, but we found the performance of the published multilingual models to be very limited. Since the multilingual models are usually pre-trained from 100+ languages, most of low-resourced languages (including Czech) are under-represented in these models. At the same time, there is a huge amount of monolingual training data available in web archives like Common Crawl. We have pre-trained and publicly released two monolingual Czech Transformers and compared them with relevant public models, trained (at least partially) for Czech. The paper presents the Transformers pre-training procedure as well as a comparison of pre-trained models on text classification task from various domains.