 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparison of Czech Transformers on Text Classification Tasks
Paper and Code
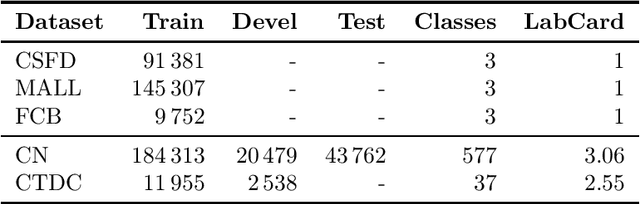
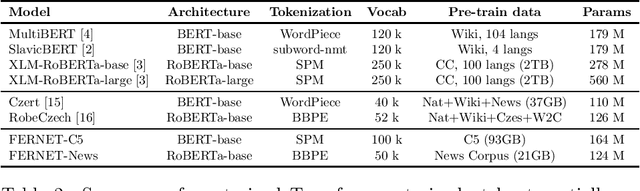
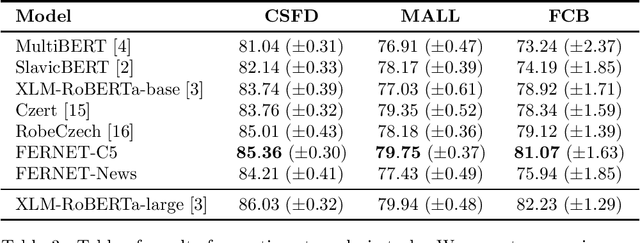
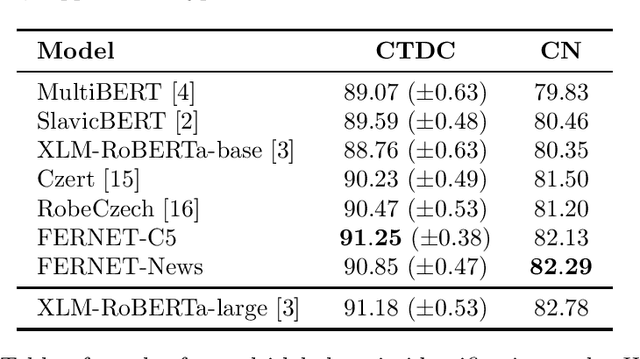
In this paper, we present our progress in pre-training monolingual Transformers for Czech and contribute to the research community by releasing our models for public. The need for such models emerged from our effort to employ Transformers in our language-specific tasks, but we found the performance of the published multilingual models to be very limited. Since the multilingual models are usually pre-trained from 100+ languages, most of low-resourced languages (including Czech) are under-represented in these models. At the same time, there is a huge amount of monolingual training data available in web archives like Common Crawl. We have pre-trained and publicly released two monolingual Czech Transformers and compared them with relevant public models, trained (at least partially) for Czech. The paper presents the Transformers pre-training procedure as well as a comparison of pre-trained models on text classification task from various domains.