 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparison of Adaptation Techniques and Recurrent Neural Network Architectures
Jul 12, 2018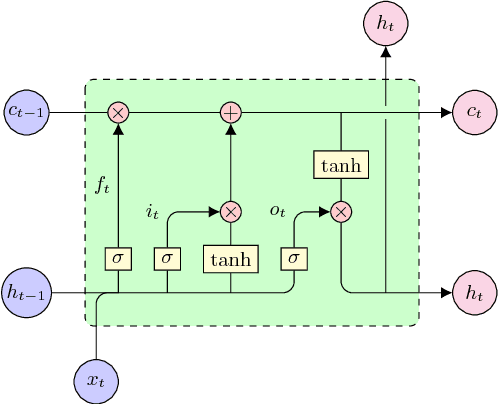
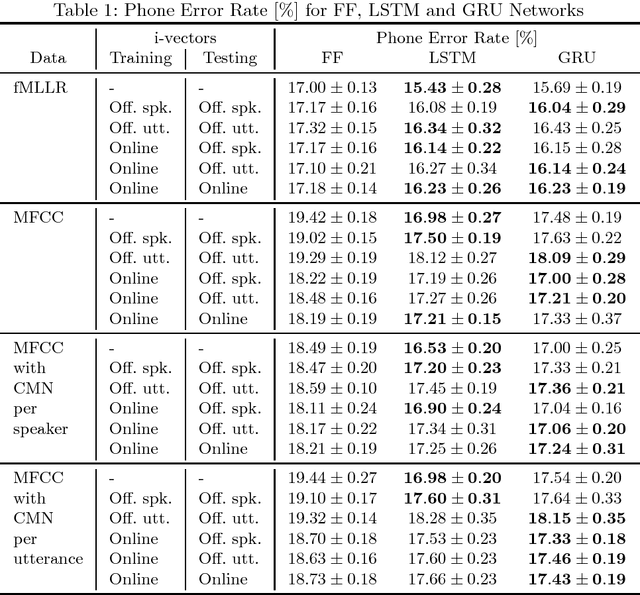

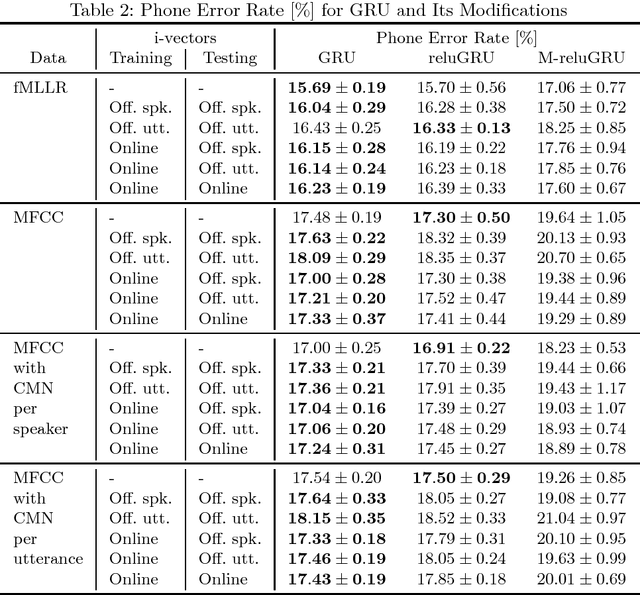
Recently, recurrent neural networks have become state-of-the-art in acoustic modeling for automatic speech recognition. The long short-term memory (LSTM) units are the most popular ones. However, alternative units like gated recurrent unit (GRU) and its modifications outperformed LSTM in some publications. In this paper, we compared five neural network (NN) architectures with various adaptation and feature normalization techniques. We have evaluated feature-space maximum likelihood linear regression, five variants of i-vector adaptation and two variants of cepstral mean normalization. The most adaptation and normalization techniques were developed for feed-forward NNs and, according to results in this paper, not all of them worked also with RNNs. For experiments, we have chosen a well known and available TIMIT phone recognition task. The phone recognition is much more sensitive to the quality of AM than large vocabulary task with a complex language model. Also, we published the open-source scripts to easily replicate the results and to help continue the development.
A Survey of Recent DNN Architectures on the TIMIT Phone Recognition Task
Jun 19, 2018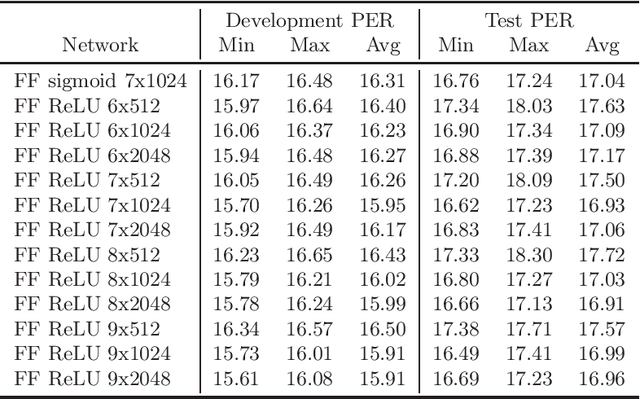
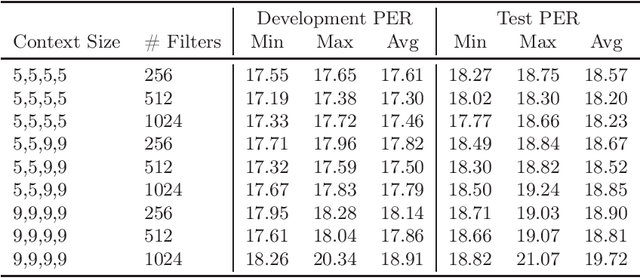

In this survey paper, we have evaluated several recent deep neural network (DNN) architectures on a TIMIT phone recognition task. We chose the TIMIT corpus due to its popularity and broad availability in the community. It also simulates a low-resource scenario that is helpful in minor languages. Also, we prefer the phone recognition task because it is much more sensitive to an acoustic model quality than a large vocabulary continuous speech recognition (LVCSR) task. In recent years, many DNN published papers reported results on TIMIT. However, the reported phone error rates (PERs) were often much higher than a PER of a simple feed-forward (FF) DNN. That was the main motivation of this paper: To provide a baseline DNNs with open-source scripts to easily replicate the baseline results for future papers with lowest possible PERs. According to our knowledge, the best-achieved PER of this survey is better than the best-published PER to date.
Recurrent DNNs and its Ensembles on the TIMIT Phone Recognition Task
Jun 19, 2018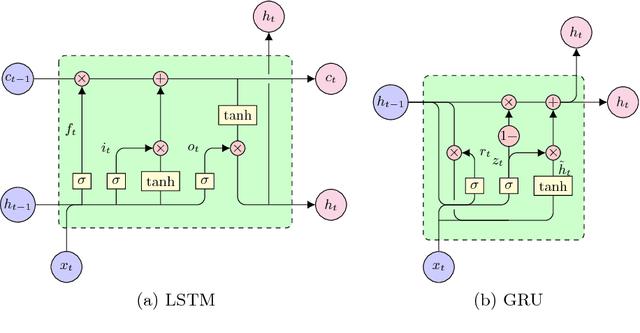
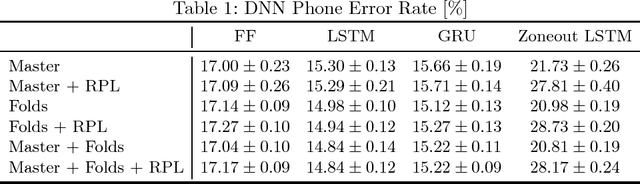
In this paper, we have investigated recurrent deep neural networks (DNNs) in combination with regularization techniques as dropout, zoneout, and regularization post-layer. As a benchmark, we chose the TIMIT phone recognition task due to its popularity and broad availability in the community. It also simulates a low-resource scenario that is helpful in minor languages. Also, we prefer the phone recognition task because it is much more sensitive to an acoustic model quality than a large vocabulary continuous speech recognition task. In recent years, recurrent DNNs pushed the error rates in automatic speech recognition down. But, there was no clear winner in proposed architectures. The dropout was used as the regularization technique in most cases, but combination with other regularization techniques together with model ensembles was omitted. However, just an ensemble of recurrent DNNs performed best and achieved an average phone error rate from 10 experiments 14.84 % (minimum 14.69 %) on core test set that is slightly lower then the best-published PER to date, according to our knowledge. Finally, in contrast of the most papers, we published the open-source scripts to easily replicate the results and to help continue the development.