 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Recent DNN Architectures on the TIMIT Phone Recognition Task
Paper and Code
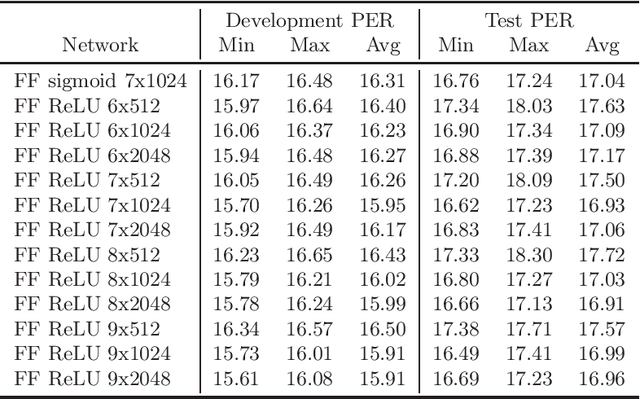
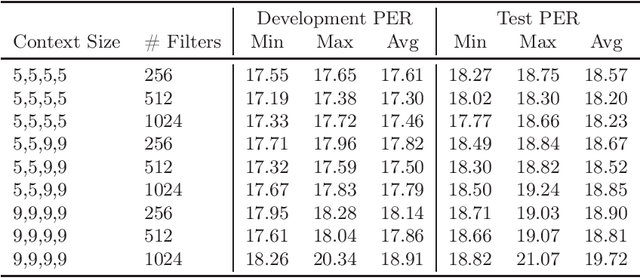

In this survey paper, we have evaluated several recent deep neural network (DNN) architectures on a TIMIT phone recognition task. We chose the TIMIT corpus due to its popularity and broad availability in the community. It also simulates a low-resource scenario that is helpful in minor languages. Also, we prefer the phone recognition task because it is much more sensitive to an acoustic model quality than a large vocabulary continuous speech recognition (LVCSR) task. In recent years, many DNN published papers reported results on TIMIT. However, the reported phone error rates (PERs) were often much higher than a PER of a simple feed-forward (FF) DNN. That was the main motivation of this paper: To provide a baseline DNNs with open-source scripts to easily replicate the baseline results for future papers with lowest possible PERs. According to our knowledge, the best-achieved PER of this survey is better than the best-published PER to date.