 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode-Switching Detection with Data-Augmented Acoustic and Language Models
Paper and Code

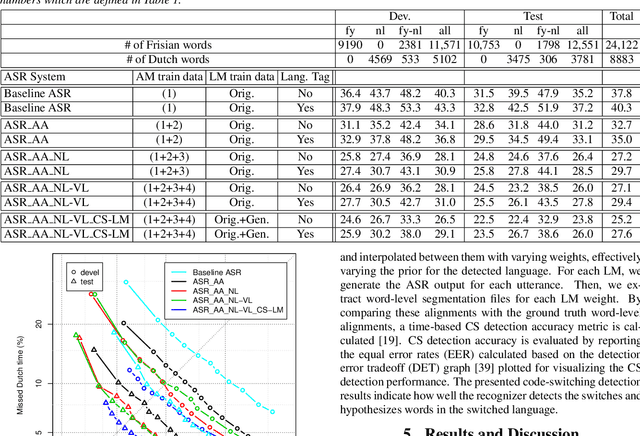
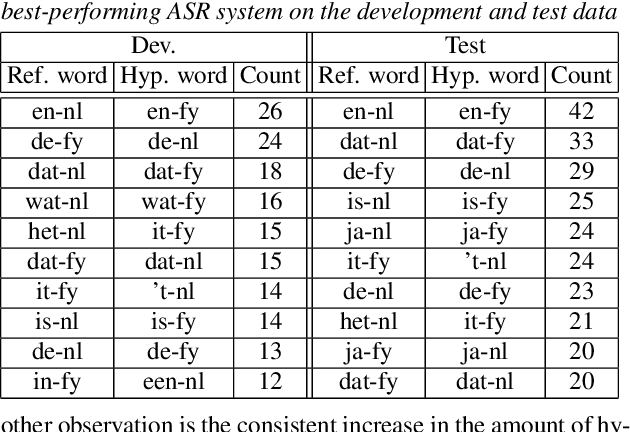

In this paper, we investigate the code-switching detection performance of a code-switching (CS) automatic speech recognition (ASR) system with data-augmented acoustic and language models. We focus on the recognition of Frisian-Dutch radio broadcasts where one of the mixed languages, namely Frisian, is under-resourced. Recently, we have explored how the acoustic modeling (AM) can benefit from monolingual speech data belonging to the high-resourced mixed language. For this purpose, we have trained state-of-the-art AMs on a significantly increased amount of CS speech by applying automatic transcription and monolingual Dutch speech. Moreover, we have improved the language model (LM) by creating CS text in various ways including text generation using recurrent LMs trained on existing CS text. Motivated by the significantly improved CS ASR performance, we delve into the CS detection performance of the same ASR system in this work by reporting CS detection accuracies together with a detailed detection error analysis.