 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Graph Decoding for Code-Switching ASR
Jun 28, 2019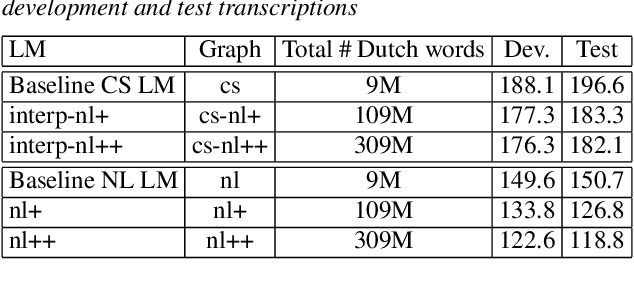

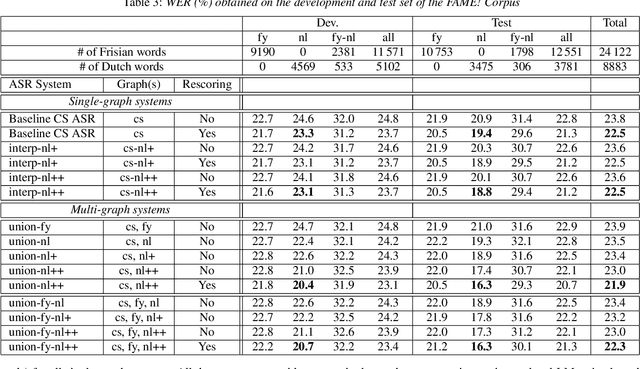
In the FAME! Project, a code-switching (CS) automatic speech recognition (ASR) system for Frisian-Dutch speech is developed that can accurately transcribe the local broadcaster's bilingual archives with CS speech. This archive contains recordings with monolingual Frisian and Dutch speech segments as well as Frisian-Dutch CS speech, hence the recognition performance on monolingual segments is also vital for accurate transcriptions. In this work, we propose a multi-graph decoding and rescoring strategy using bilingual and monolingual graphs together with a unified acoustic model for CS ASR. The proposed decoding scheme gives the freedom to design and employ alternative search spaces for each (monolingual or bilingual) recognition task and enables the effective use of monolingual resources of the high-resourced mixed language in low-resourced CS scenarios. In our scenario, Dutch is the high-resourced and Frisian is the low-resourced language. We therefore use additional monolingual Dutch text resources to improve the Dutch language model (LM) and compare the performance of single- and multi-graph CS ASR systems on Dutch segments using larger Dutch LMs. The ASR results show that the proposed approach outperforms baseline single-graph CS ASR systems, providing better performance on the monolingual Dutch segments without any accuracy loss on monolingual Frisian and code-mixed segments.
A comparison of linear and non-linear calibrations for speaker recognition
Apr 09, 2014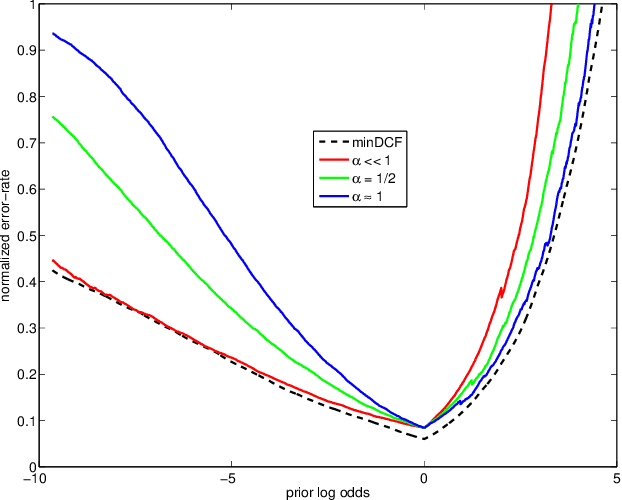
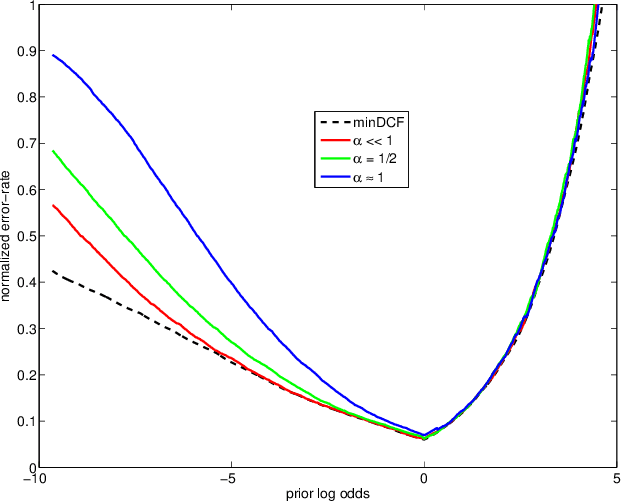
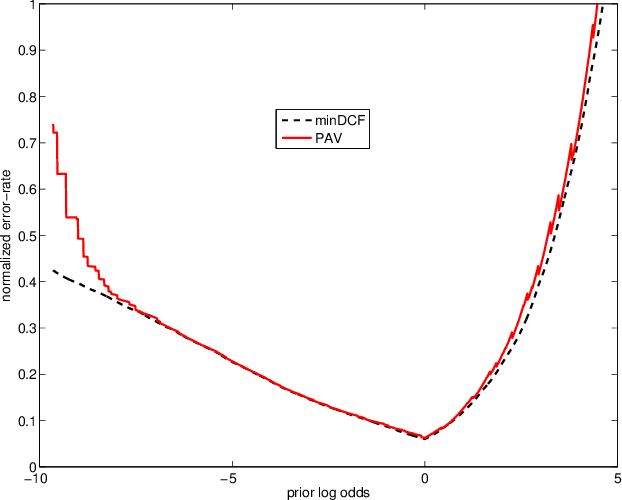
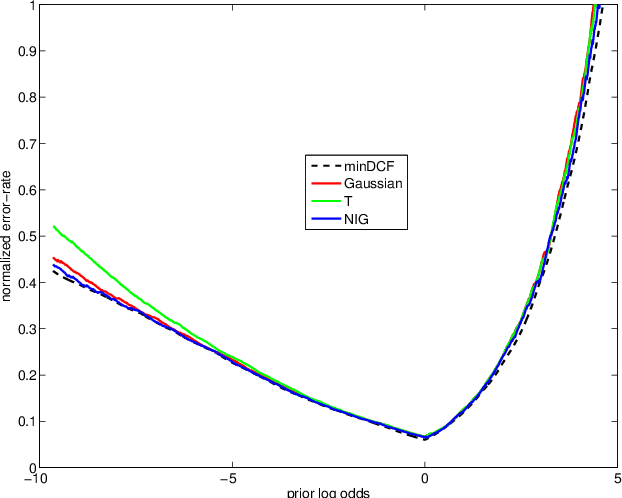
In recent work on both generative and discriminative score to log-likelihood-ratio calibration, it was shown that linear transforms give good accuracy only for a limited range of operating points. Moreover, these methods required tailoring of the calibration training objective functions in order to target the desired region of best accuracy. Here, we generalize the linear recipes to non-linear ones. We experiment with a non-linear, non-parametric, discriminative PAV solution, as well as parametric, generative, maximum-likelihood solutions that use Gaussian, Student's T and normal-inverse-Gaussian score distributions. Experiments on NIST SRE'12 scores suggest that the non-linear methods provide wider ranges of optimal accuracy and can be trained without having to resort to objective function tailoring.