Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-task learning of speech and speaker recognition
Paper and Code
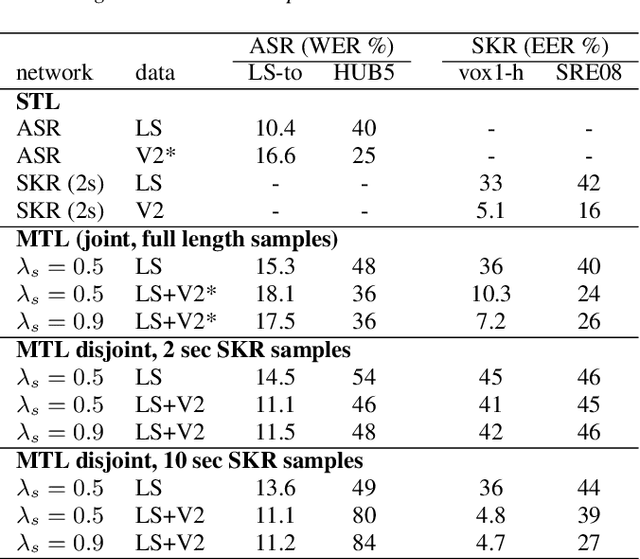
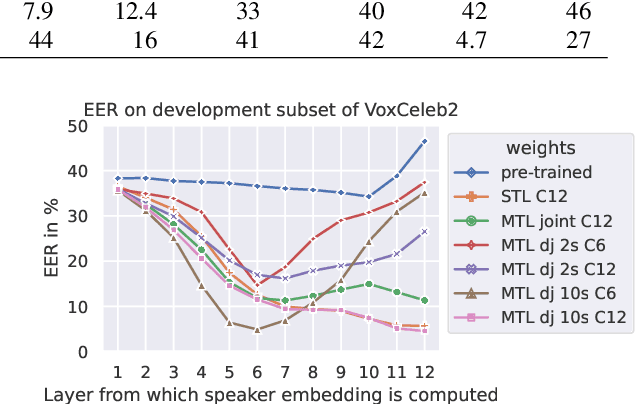
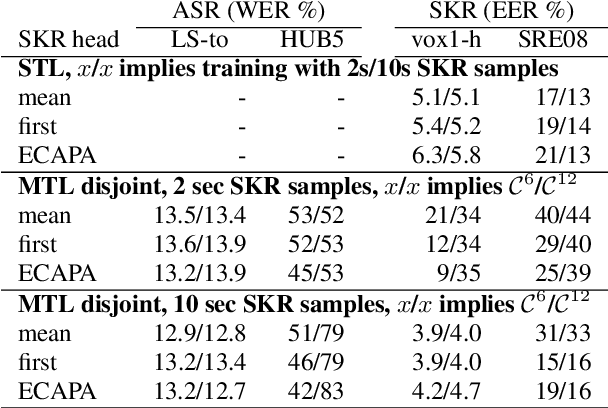

We study multi-task learning for two orthogonal speech technology tasks: speech and speaker recognition. We use wav2vec2 as a base architecture with two task-specific output heads. We experiment with different methods to mix speaker and speech information in the output embedding sequence, and propose a simple dynamic approach to balance the speech and speaker recognition loss functions. Our multi-task learning networks can produce a shared speaker and speech embedding, which are evaluated on the LibriSpeech and VoxCeleb test sets, and achieve a performance comparable to separate single-task models. Code is available at https://github.com/nikvaessen/2022-repo-mt-w2v2.
* submitted to ICML 2022
View paper on