Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-tuning wav2vec2 for speaker recognition
Paper and Code
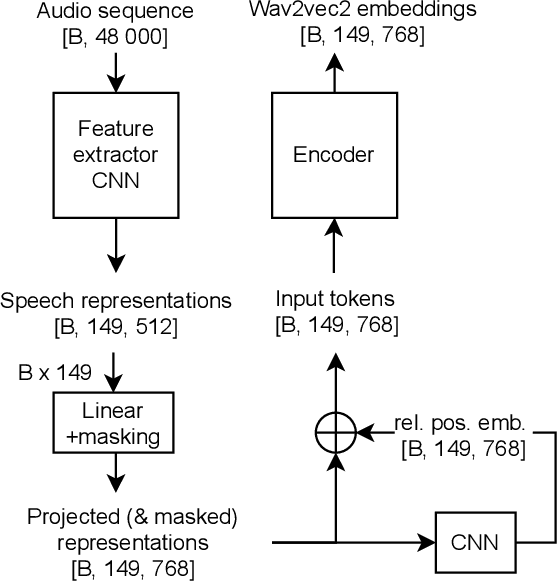
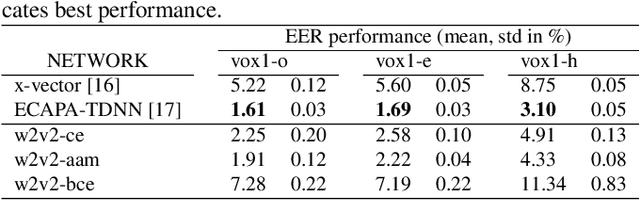
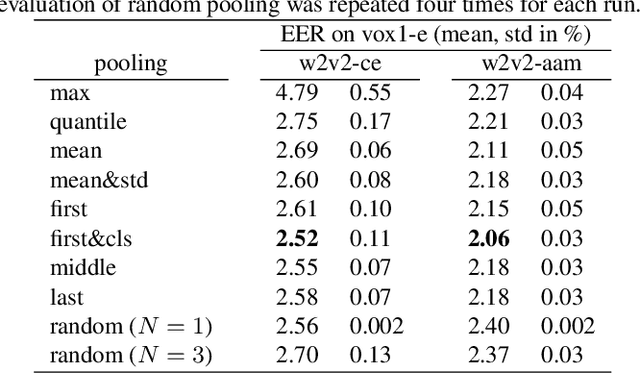
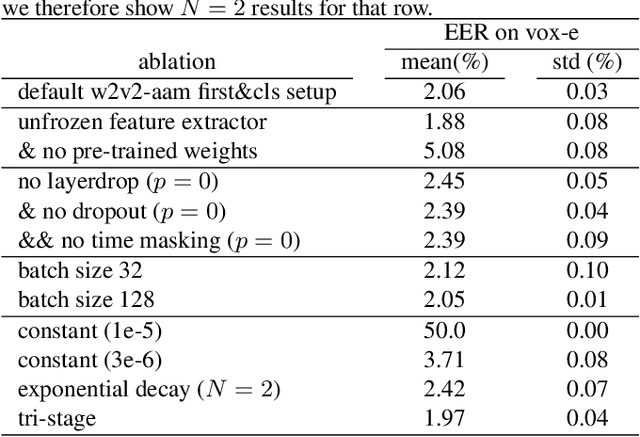
This paper explores applying the wav2vec2 framework to speaker recognition instead of speech recognition. We study the effectiveness of the pre-trained weights on the speaker recognition task, and how to pool the wav2vec2 output sequence into a fixed-length speaker embedding. To adapt the framework to speaker recognition, we propose a single-utterance classification variant with CE or AAM softmax loss, and an utterance-pair classification variant with BCE loss. Our best performing variant, w2v2-aam, achieves a 1.88% EER on the extended voxceleb1 test set compared to 1.69% EER with an ECAPA-TDNN baseline. Code is available at https://github.com/nikvaessen/w2v2-speaker.
* under review for ICASSP 2022
View paper on