 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effect of Batch Size on Contrastive Self-Supervised Speech Representation Learning
Paper and Code
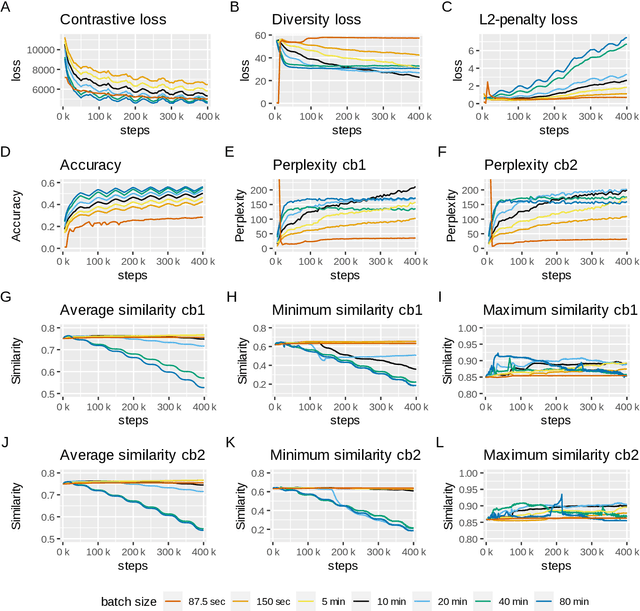
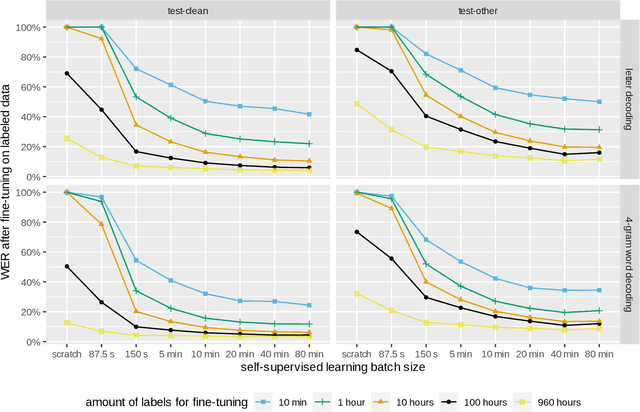
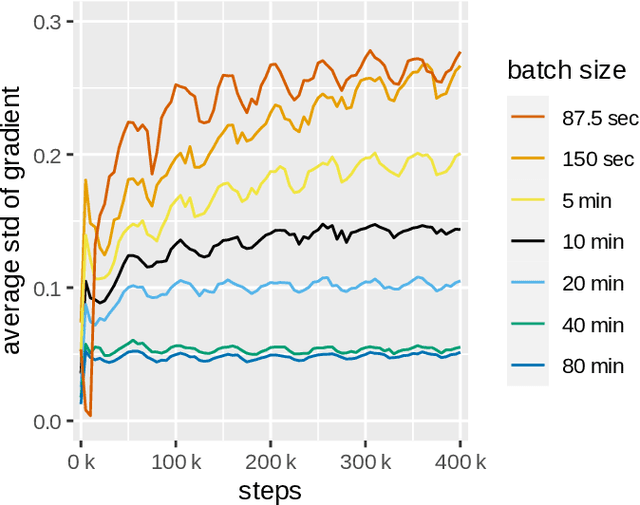
Foundation models in speech are often trained using many GPUs, which implicitly leads to large effective batch sizes. In this paper we study the effect of batch size on pre-training, both in terms of statistics that can be monitored during training, and in the effect on the performance of a downstream fine-tuning task. By using batch sizes varying from 87.5 seconds to 80 minutes of speech we show that, for a fixed amount of iterations, larger batch sizes result in better pre-trained models. However, there is lower limit for stability, and an upper limit for effectiveness. We then show that the quality of the pre-trained model depends mainly on the amount of speech data seen during training, i.e., on the product of batch size and number of iterations. All results are produced with an independent implementation of the wav2vec 2.0 architecture, which to a large extent reproduces the results of the original work (arXiv:2006.11477). Our extensions can help researchers choose effective operating conditions when studying self-supervised learning in speech, and hints towards benchmarking self-supervision with a fixed amount of seen data. Code and model checkpoints are available at https://github.com/nikvaessen/w2v2-batch-size.