 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Domains to Instances: Dual-Granularity Data Synthesis for LLM Unlearning
Jan 07, 2026Although machine unlearning is essential for removing private, harmful, or copyrighted content from LLMs, current benchmarks often fail to faithfully represent the true "forgetting scope" learned by the model. We formalize two distinct unlearning granularities, domain-level and instance-level, and propose BiForget, an automated framework for synthesizing high-quality forget sets. Unlike prior work relying on external generators, BiForget exploits the target model per se to elicit data that matches its internal knowledge distribution through seed-guided and adversarial prompting. Our experiments across diverse benchmarks show that it achieves a superior balance of relevance, diversity, and efficiency. Quantitatively, in the Harry Potter domain, it improves relevance by ${\sim}20$ and diversity by ${\sim}$0.05 while halving the total data size compared to SOTAs. Ultimately, it facilitates more robust forgetting and better utility preservation, providing a more rigorous foundation for evaluating LLM unlearning.
MCIP: Protecting MCP Safety via Model Contextual Integrity Protocol
May 21, 2025As Model Context Protocol (MCP) introduces an easy-to-use ecosystem for users and developers, it also brings underexplored safety risks. Its decentralized architecture, which separates clients and servers, poses unique challenges for systematic safety analysis. This paper proposes a novel framework to enhance MCP safety. Guided by the MAESTRO framework, we first analyze the missing safety mechanisms in MCP, and based on this analysis, we propose the Model Contextual Integrity Protocol (MCIP), a refined version of MCP that addresses these gaps. Next, we develop a fine-grained taxonomy that captures a diverse range of unsafe behaviors observed in MCP scenarios. Building on this taxonomy, we develop benchmark and training data that support the evaluation and improvement of LLMs' capabilities in identifying safety risks within MCP interactions. Leveraging the proposed benchmark and training data, we conduct extensive experiments on state-of-the-art LLMs. The results highlight LLMs' vulnerabilities in MCP interactions and demonstrate that our approach substantially improves their safety performance.
Context Reasoner: Incentivizing Reasoning Capability for Contextualized Privacy and Safety Compliance via Reinforcement Learning
May 20, 2025While Large Language Models (LLMs) exhibit remarkable capabilities, they also introduce significant safety and privacy risks. Current mitigation strategies often fail to preserve contextual reasoning capabilities in risky scenarios. Instead, they rely heavily on sensitive pattern matching to protect LLMs, which limits the scope. Furthermore, they overlook established safety and privacy standards, leading to systemic risks for legal compliance. To address these gaps, we formulate safety and privacy issues into contextualized compliance problems following the Contextual Integrity (CI) theory. Under the CI framework, we align our model with three critical regulatory standards: GDPR, EU AI Act, and HIPAA. Specifically, we employ reinforcement learning (RL) with a rule-based reward to incentivize contextual reasoning capabilities while enhancing compliance with safety and privacy norms. Through extensive experiments, we demonstrate that our method not only significantly enhances legal compliance (achieving a +17.64% accuracy improvement in safety/privacy benchmarks) but also further improves general reasoning capability. For OpenThinker-7B, a strong reasoning model that significantly outperforms its base model Qwen2.5-7B-Instruct across diverse subjects, our method enhances its general reasoning capabilities, with +2.05% and +8.98% accuracy improvement on the MMLU and LegalBench benchmark, respectively.
PrivaCI-Bench: Evaluating Privacy with Contextual Integrity and Legal Compliance
Feb 24, 2025Recent advancements in generative large language models (LLMs) have enabled wider applicability, accessibility, and flexibility. However, their reliability and trustworthiness are still in doubt, especially for concerns regarding individuals' data privacy. Great efforts have been made on privacy by building various evaluation benchmarks to study LLMs' privacy awareness and robustness from their generated outputs to their hidden representations. Unfortunately, most of these works adopt a narrow formulation of privacy and only investigate personally identifiable information (PII). In this paper, we follow the merit of the Contextual Integrity (CI) theory, which posits that privacy evaluation should not only cover the transmitted attributes but also encompass the whole relevant social context through private information flows. We present PrivaCI-Bench, a comprehensive contextual privacy evaluation benchmark targeted at legal compliance to cover well-annotated privacy and safety regulations, real court cases, privacy policies, and synthetic data built from the official toolkit to study LLMs' privacy and safety compliance. We evaluate the latest LLMs, including the recent reasoner models QwQ-32B and Deepseek R1. Our experimental results suggest that though LLMs can effectively capture key CI parameters inside a given context, they still require further advancements for privacy compliance.
Privacy Checklist: Privacy Violation Detection Grounding on Contextual Integrity Theory
Aug 19, 2024



Privacy research has attracted wide attention as individuals worry that their private data can be easily leaked during interactions with smart devices, social platforms, and AI applications. Computer science researchers, on the other hand, commonly study privacy issues through privacy attacks and defenses on segmented fields. Privacy research is conducted on various sub-fields, including Computer Vision (CV), Natural Language Processing (NLP), and Computer Networks. Within each field, privacy has its own formulation. Though pioneering works on attacks and defenses reveal sensitive privacy issues, they are narrowly trapped and cannot fully cover people's actual privacy concerns. Consequently, the research on general and human-centric privacy research remains rather unexplored. In this paper, we formulate the privacy issue as a reasoning problem rather than simple pattern matching. We ground on the Contextual Integrity (CI) theory which posits that people's perceptions of privacy are highly correlated with the corresponding social context. Based on such an assumption, we develop the first comprehensive checklist that covers social identities, private attributes, and existing privacy regulations. Unlike prior works on CI that either cover limited expert annotated norms or model incomplete social context, our proposed privacy checklist uses the whole Health Insurance Portability and Accountability Act of 1996 (HIPAA) as an example, to show that we can resort to large language models (LLMs) to completely cover the HIPAA's regulations. Additionally, our checklist also gathers expert annotations across multiple ontologies to determine private information including but not limited to personally identifiable information (PII). We use our preliminary results on the HIPAA to shed light on future context-centric privacy research to cover more privacy regulations, social norms and standards.
SoK: Privacy-preserving Deep Learning with Homomorphic Encryption
Jan 01, 2022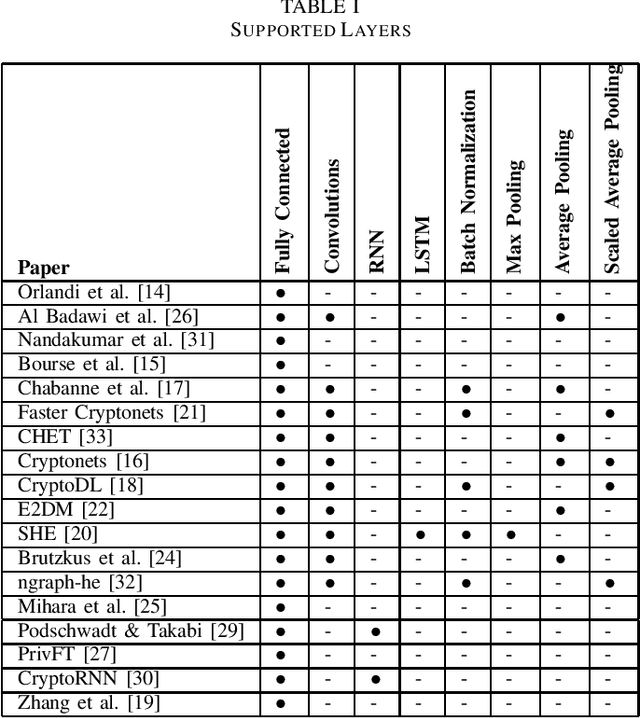
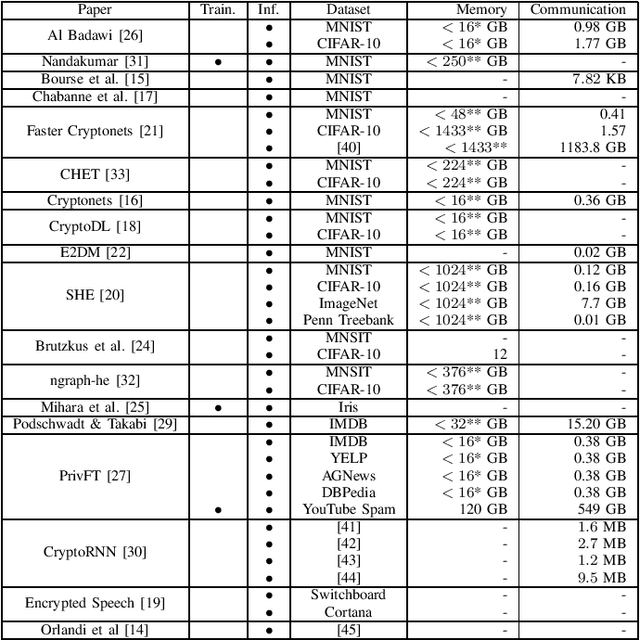
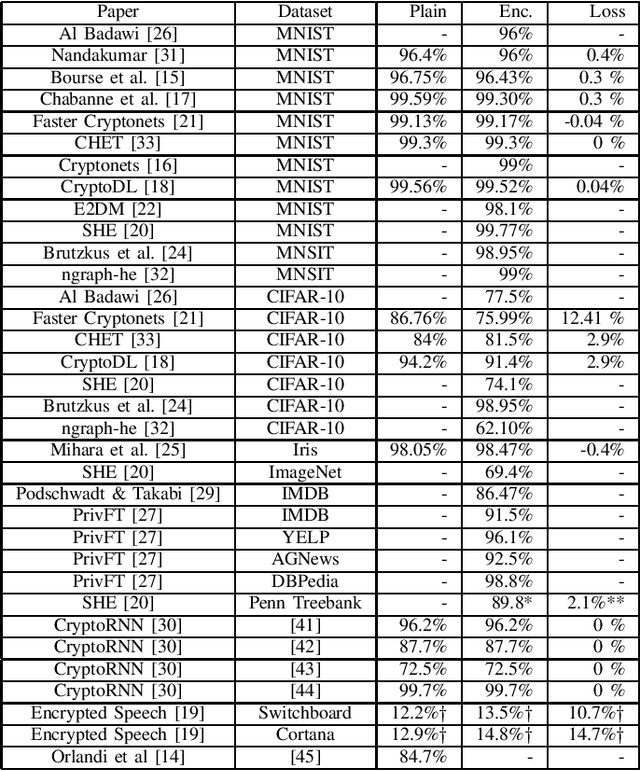
Outsourced computation for neural networks allows users access to state of the art models without needing to invest in specialized hardware and know-how. The problem is that the users lose control over potentially privacy sensitive data. With homomorphic encryption (HE) computation can be performed on encrypted data without revealing its content. In this systematization of knowledge, we take an in-depth look at approaches that combine neural networks with HE for privacy preservation. We categorize the changes to neural network models and architectures to make them computable over HE and how these changes impact performance. We find numerous challenges to HE based privacy-preserving deep learning such as computational overhead, usability, and limitations posed by the encryption schemes.
Collaborative Homomorphic Computation on Data Encrypted under Multiple Keys
Nov 11, 2019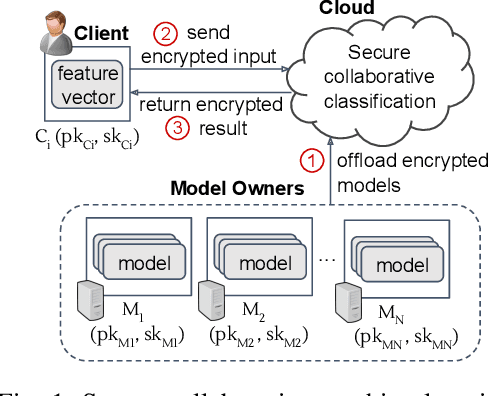
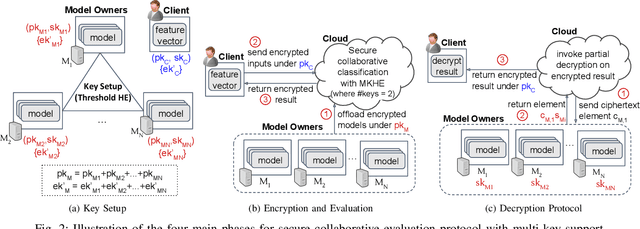

Homomorphic encryption (HE) is a promising cryptographic technique for enabling secure collaborative machine learning in the cloud. However, support for homomorphic computation on ciphertexts under multiple keys is inefficient. Current solutions often require key setup before any computation or incur large ciphertext size (at best, grow linearly to the number of involved keys). In this paper, we proposed a new approach that leverages threshold and multi-key HE to support computations on ciphertexts under different keys. Our new approach removes the need for key setup between each client and the set of model owners. At the same time, this approach reduces the number of encrypted models to be offloaded to the cloud evaluator, and the ciphertext size with a dimension reduction from (N+1)x2 to 2x2. We present the details of each step and discuss the complexity and security of our approach.