 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaplace-Bridged Randomized Smoothing for Fast Certified Robustness
Apr 27, 2026Randomized Smoothing (RS) offers formal $\ell_2$ guarantees for arbitrary base classifiers but faces two key practical bottlenecks: (i) it often relies on noise-augmented training to achieve nontrivial certificates, which increases training cost, can reduce clean accuracy, and weakens RS as a genuinely post-hoc defense; and (ii) certification is computationally expensive, typically requiring tens of thousands of noisy forward passes per input, which hinders deployment, especially on resource-constrained edge devices. To address both limitations, we propose Laplace-Bridged Smoothing (LBS), an analytic reformulation of RS that replaces high-dimensional input-space Monte Carlo (MC) sampling with efficient computations in a low-dimensional probability space. LBS preserves formal robustness guarantees without requiring noise-augmented training while substantially reducing certification burden. On CIFAR-10 and ImageNet, LBS attains stronger certified robustness than RS and reduces per-sample certification cost by nearly an order of magnitude. Notably, on NVIDIA Jetson Orin Nano and Raspberry Pi 4, LBS achieves speedups of up to $494\times$, enabling practical certified deployment on real-world edge devices. Finally, we provide theoretical justification for the analytic formulation and certificate validity of LBS.
MCP-DPT: A Defense-Placement Taxonomy and Coverage Analysis for Model Context Protocol Security
Apr 08, 2026The Model Context Protocol (MCP) enables large language models (LLMs) to dynamically discover and invoke third-party tools, significantly expanding agent capabilities while introducing a distinct security landscape. Unlike prompt-only interactions, MCP exposes pre-execution artifacts, shared context, multi-turn workflows, and third-party supply chains to adversarial influence across independently operated components. While recent work has identified MCP-specific attacks and evaluated defenses, existing studies are largely attack-centric or benchmark-driven, providing limited guidance on where mitigation responsibility should reside within the MCP architecture. This is problematic given MCP's multi-party design and distributed trust boundaries. We present a defense-placement-oriented security analysis of MCP, introducing a layer-aligned taxonomy that organizes attacks by the architectural component responsible for enforcement. Threats are mapped across six MCP layers, and primary and secondary defense points are identified to support principled defense-in-depth reasoning under adversaries controlling tools, servers, or ecosystem components. A structured mapping of existing academic and industry defenses onto this framework reveals uneven and predominantly tool-centric protection, with persistent gaps at the host orchestration, transport, and supply-chain layers. These findings suggest that many MCP security weaknesses stem from architectural misalignment rather than isolated implementation flaws.
SSCAE -- Semantic, Syntactic, and Context-aware natural language Adversarial Examples generator
Mar 18, 2024Machine learning models are vulnerable to maliciously crafted Adversarial Examples (AEs). Training a machine learning model with AEs improves its robustness and stability against adversarial attacks. It is essential to develop models that produce high-quality AEs. Developing such models has been much slower in natural language processing (NLP) than in areas such as computer vision. This paper introduces a practical and efficient adversarial attack model called SSCAE for \textbf{S}emantic, \textbf{S}yntactic, and \textbf{C}ontext-aware natural language \textbf{AE}s generator. SSCAE identifies important words and uses a masked language model to generate an early set of substitutions. Next, two well-known language models are employed to evaluate the initial set in terms of semantic and syntactic characteristics. We introduce (1) a dynamic threshold to capture more efficient perturbations and (2) a local greedy search to generate high-quality AEs. As a black-box method, SSCAE generates humanly imperceptible and context-aware AEs that preserve semantic consistency and the source language's syntactical and grammatical requirements. The effectiveness and superiority of the proposed SSCAE model are illustrated with fifteen comparative experiments and extensive sensitivity analysis for parameter optimization. SSCAE outperforms the existing models in all experiments while maintaining a higher semantic consistency with a lower query number and a comparable perturbation rate.
RobustSentEmbed: Robust Sentence Embeddings Using Adversarial Self-Supervised Contrastive Learning
Mar 17, 2024Pre-trained language models (PLMs) have consistently demonstrated outstanding performance across a diverse spectrum of natural language processing tasks. Nevertheless, despite their success with unseen data, current PLM-based representations often exhibit poor robustness in adversarial settings. In this paper, we introduce RobustSentEmbed, a self-supervised sentence embedding framework designed to improve both generalization and robustness in diverse text representation tasks and against a diverse set of adversarial attacks. Through the generation of high-risk adversarial perturbations and their utilization in a novel objective function, RobustSentEmbed adeptly learns high-quality and robust sentence embeddings. Our experiments confirm the superiority of RobustSentEmbed over state-of-the-art representations. Specifically, Our framework achieves a significant reduction in the success rate of various adversarial attacks, notably reducing the BERTAttack success rate by almost half (from 75.51\% to 38.81\%). The framework also yields improvements of 1.59\% and 0.23\% in semantic textual similarity tasks and various transfer tasks, respectively.
I can't see it but I can Fine-tune it: On Encrypted Fine-tuning of Transformers using Fully Homomorphic Encryption
Feb 14, 2024


In today's machine learning landscape, fine-tuning pretrained transformer models has emerged as an essential technique, particularly in scenarios where access to task-aligned training data is limited. However, challenges surface when data sharing encounters obstacles due to stringent privacy regulations or user apprehension regarding personal information disclosure. Earlier works based on secure multiparty computation (SMC) and fully homomorphic encryption (FHE) for privacy-preserving machine learning (PPML) focused more on privacy-preserving inference than privacy-preserving training. In response, we introduce BlindTuner, a privacy-preserving fine-tuning system that enables transformer training exclusively on homomorphically encrypted data for image classification. Our extensive experimentation validates BlindTuner's effectiveness by demonstrating comparable accuracy to non-encrypted models. Notably, our findings highlight a substantial speed enhancement of 1.5x to 600x over previous work in this domain.
MedBlindTuner: Towards Privacy-preserving Fine-tuning on Biomedical Images with Transformers and Fully Homomorphic Encryption
Jan 17, 2024Advancements in machine learning (ML) have significantly revolutionized medical image analysis, prompting hospitals to rely on external ML services. However, the exchange of sensitive patient data, such as chest X-rays, poses inherent privacy risks when shared with third parties. Addressing this concern, we propose MedBlindTuner, a privacy-preserving framework leveraging fully homomorphic encryption (FHE) and a data-efficient image transformer (DEiT). MedBlindTuner enables the training of ML models exclusively on FHE-encrypted medical images. Our experimental evaluation demonstrates that MedBlindTuner achieves comparable accuracy to models trained on non-encrypted images, offering a secure solution for outsourcing ML computations while preserving patient data privacy. To the best of our knowledge, this is the first work that uses data-efficient image transformers and fully homomorphic encryption in this domain.
SoK: Privacy Preserving Machine Learning using Functional Encryption: Opportunities and Challenges
Apr 11, 2022



With the advent of functional encryption, new possibilities for computation on encrypted data have arisen. Functional Encryption enables data owners to grant third-party access to perform specified computations without disclosing their inputs. It also provides computation results in plain, unlike Fully Homomorphic Encryption. The ubiquitousness of machine learning has led to the collection of massive private data in the cloud computing environment. This raises potential privacy issues and the need for more private and secure computing solutions. Numerous efforts have been made in privacy-preserving machine learning (PPML) to address security and privacy concerns. There are approaches based on fully homomorphic encryption (FHE), secure multiparty computation (SMC), and, more recently, functional encryption (FE). However, FE-based PPML is still in its infancy and has not yet gotten much attention compared to FHE-based PPML approaches. In this paper, we provide a systematization of PPML works based on FE summarizing state-of-the-art in the literature. We focus on Inner-product-FE and Quadratic-FE-based machine learning models for the PPML applications. We analyze the performance and usability of the available FE libraries and their applications to PPML. We also discuss potential directions for FE-based PPML approaches. To the best of our knowledge, this is the first work to systematize FE-based PPML approaches.
SoK: Privacy-preserving Deep Learning with Homomorphic Encryption
Jan 01, 2022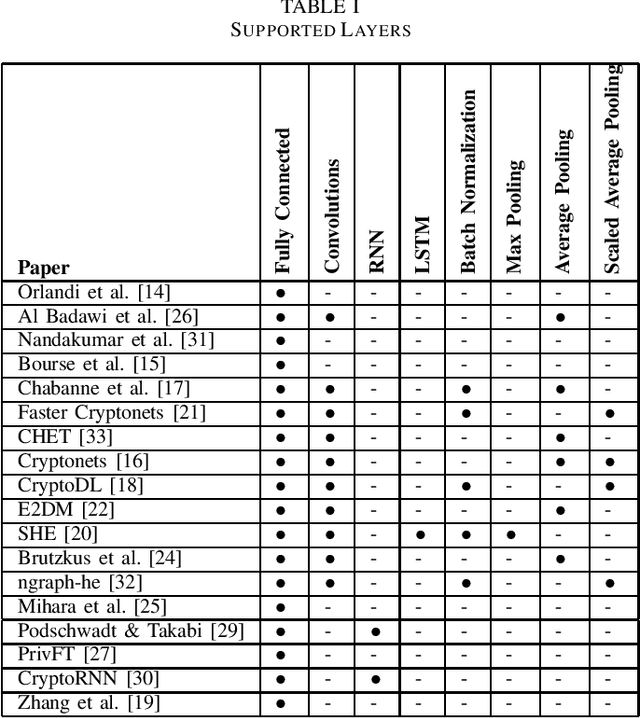
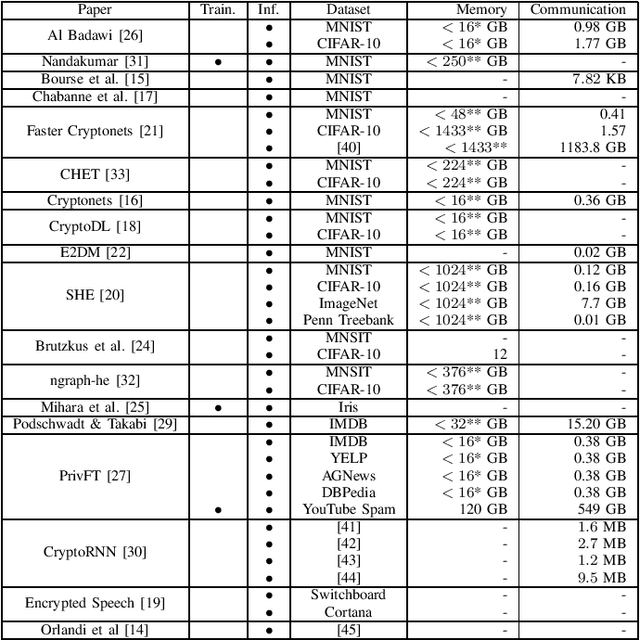
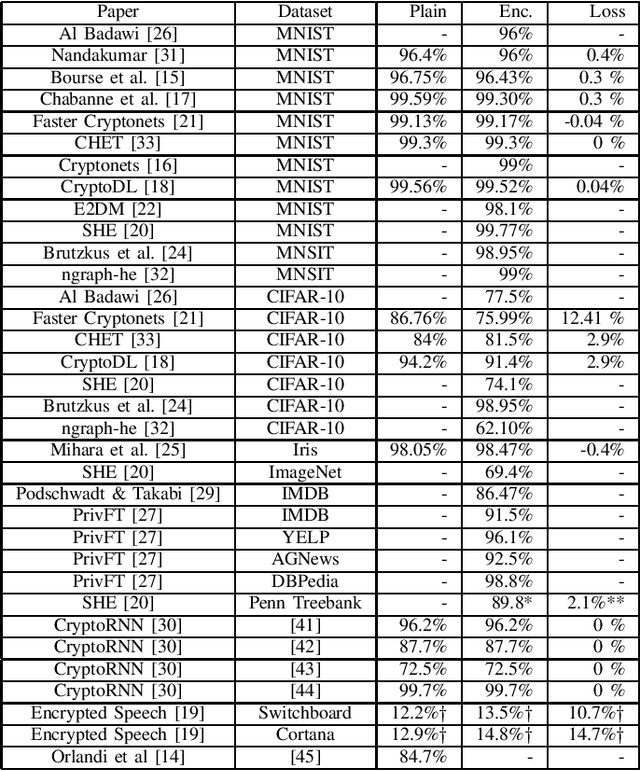
Outsourced computation for neural networks allows users access to state of the art models without needing to invest in specialized hardware and know-how. The problem is that the users lose control over potentially privacy sensitive data. With homomorphic encryption (HE) computation can be performed on encrypted data without revealing its content. In this systematization of knowledge, we take an in-depth look at approaches that combine neural networks with HE for privacy preservation. We categorize the changes to neural network models and architectures to make them computable over HE and how these changes impact performance. We find numerous challenges to HE based privacy-preserving deep learning such as computational overhead, usability, and limitations posed by the encryption schemes.
Privacy preserving Neural Network Inference on Encrypted Data with GPUs
Nov 26, 2019
Machine Learning as a Service (MLaaS) has become a growing trend in recent years and several such services are currently offered. MLaaS is essentially a set of services that provides machine learning tools and capabilities as part of cloud computing services. In these settings, the cloud has pre-trained models that are deployed and large computing capacity whereas the clients can use these models to make predictions without having to worry about maintaining the models and the service. However, the main concern with MLaaS is the privacy of the client's data. Although there have been several proposed approaches in the literature to run machine learning models on encrypted data, the performance is still far from being satisfactory for practical use. In this paper, we aim to accelerate the performance of running machine learning on encrypted data using combination of Fully Homomorphic Encryption (FHE), Convolutional Neural Networks (CNNs) and Graphics Processing Units (GPUs). We use a number of optimization techniques, and efficient GPU-based implementation to achieve high performance. We evaluate a CNN whose architecture is similar to AlexNet to classify homomorphically encrypted samples from the Cars Overhead With Context (COWC) dataset. To the best of our knowledge, it is the first time such a complex network and large dataset is evaluated on encrypted data. Our approach achieved reasonable classification accuracy of 95% for the COWC dataset. In terms of performance, our results show that we could achieve several thousands times speed up when we implement GPU-accelerated FHE operations on encrypted floating point numbers.