 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSCAE -- Semantic, Syntactic, and Context-aware natural language Adversarial Examples generator
Mar 18, 2024Machine learning models are vulnerable to maliciously crafted Adversarial Examples (AEs). Training a machine learning model with AEs improves its robustness and stability against adversarial attacks. It is essential to develop models that produce high-quality AEs. Developing such models has been much slower in natural language processing (NLP) than in areas such as computer vision. This paper introduces a practical and efficient adversarial attack model called SSCAE for \textbf{S}emantic, \textbf{S}yntactic, and \textbf{C}ontext-aware natural language \textbf{AE}s generator. SSCAE identifies important words and uses a masked language model to generate an early set of substitutions. Next, two well-known language models are employed to evaluate the initial set in terms of semantic and syntactic characteristics. We introduce (1) a dynamic threshold to capture more efficient perturbations and (2) a local greedy search to generate high-quality AEs. As a black-box method, SSCAE generates humanly imperceptible and context-aware AEs that preserve semantic consistency and the source language's syntactical and grammatical requirements. The effectiveness and superiority of the proposed SSCAE model are illustrated with fifteen comparative experiments and extensive sensitivity analysis for parameter optimization. SSCAE outperforms the existing models in all experiments while maintaining a higher semantic consistency with a lower query number and a comparable perturbation rate.
RobustSentEmbed: Robust Sentence Embeddings Using Adversarial Self-Supervised Contrastive Learning
Mar 17, 2024Pre-trained language models (PLMs) have consistently demonstrated outstanding performance across a diverse spectrum of natural language processing tasks. Nevertheless, despite their success with unseen data, current PLM-based representations often exhibit poor robustness in adversarial settings. In this paper, we introduce RobustSentEmbed, a self-supervised sentence embedding framework designed to improve both generalization and robustness in diverse text representation tasks and against a diverse set of adversarial attacks. Through the generation of high-risk adversarial perturbations and their utilization in a novel objective function, RobustSentEmbed adeptly learns high-quality and robust sentence embeddings. Our experiments confirm the superiority of RobustSentEmbed over state-of-the-art representations. Specifically, Our framework achieves a significant reduction in the success rate of various adversarial attacks, notably reducing the BERTAttack success rate by almost half (from 75.51\% to 38.81\%). The framework also yields improvements of 1.59\% and 0.23\% in semantic textual similarity tasks and various transfer tasks, respectively.
GLEAKE: Global and Local Embedding Automatic Keyphrase Extraction
May 19, 2020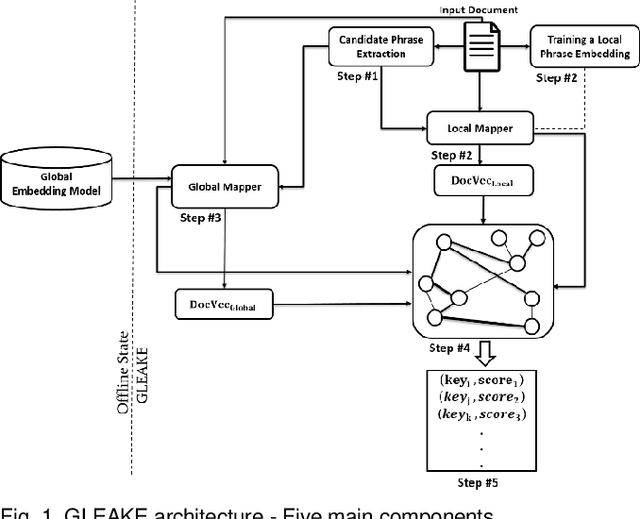
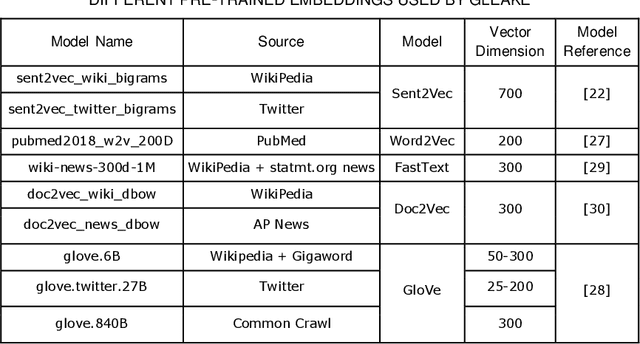
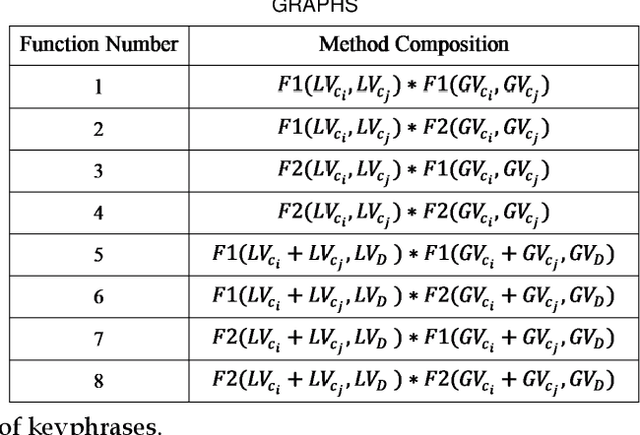
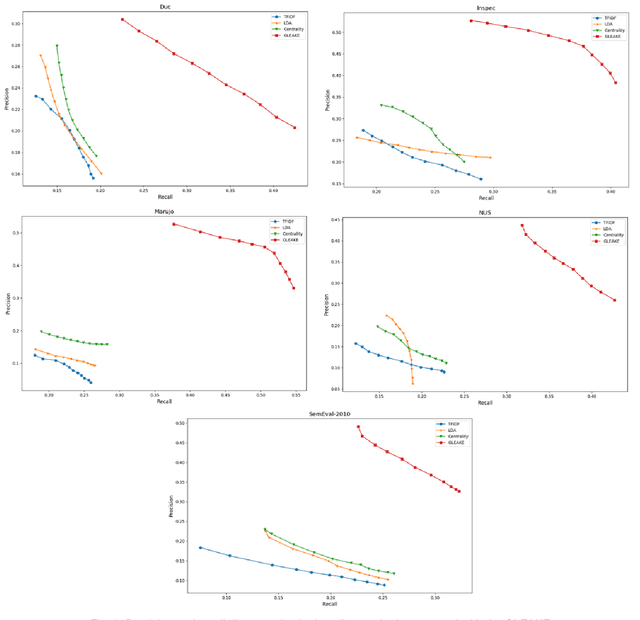
Automated methods for granular categorization of large corpora of text documents have become increasingly more important with the rate scientific, news, medical, and web documents are growing in the last few years. Automatic keyphrase extraction (AKE) aims to automatically detect a small set of single or multi-words from within a single textual document that captures the main topics of the document. AKE plays an important role in various NLP and information retrieval tasks such as document summarization and categorization, full-text indexing, and article recommendation. Due to the lack of sufficient human-labeled data in different textual contents, supervised learning approaches are not ideal for automatic detection of keyphrases from the content of textual bodies. With the state-of-the-art advances in text embedding techniques, NLP researchers have focused on developing unsupervised methods to obtain meaningful insights from raw datasets. In this work, we introduce Global and Local Embedding Automatic Keyphrase Extractor (GLEAKE) for the task of AKE. GLEAKE utilizes single and multi-word embedding techniques to explore the syntactic and semantic aspects of the candidate phrases and then combines them into a series of embedding-based graphs. Moreover, GLEAKE applies network analysis techniques on each embedding-based graph to refine the most significant phrases as a final set of keyphrases. We demonstrate the high performance of GLEAKE by evaluating its results on five standard AKE datasets from different domains and writing styles and by showing its superiority with regards to other state-of-the-art methods.