 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLEAKE: Global and Local Embedding Automatic Keyphrase Extraction
Paper and Code
May 19, 2020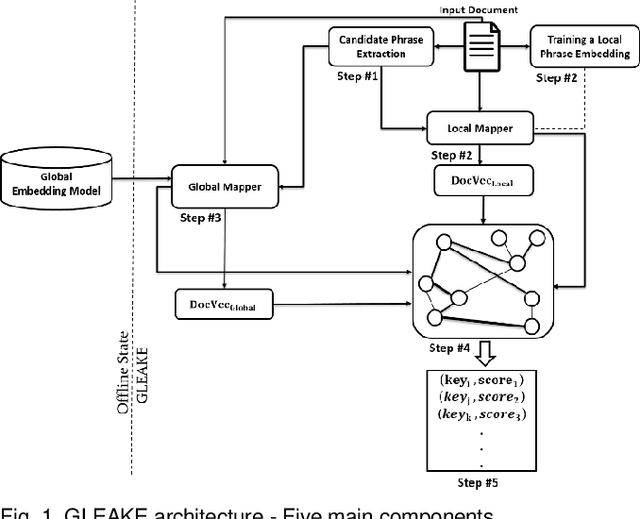
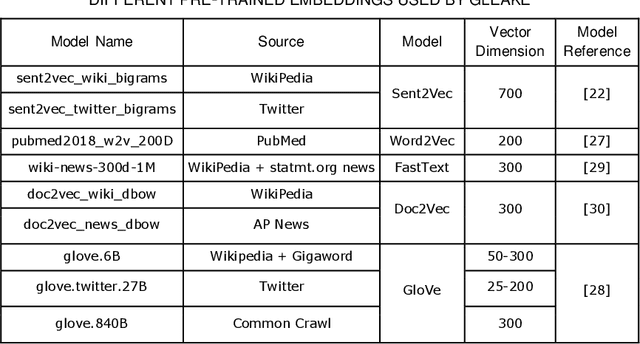
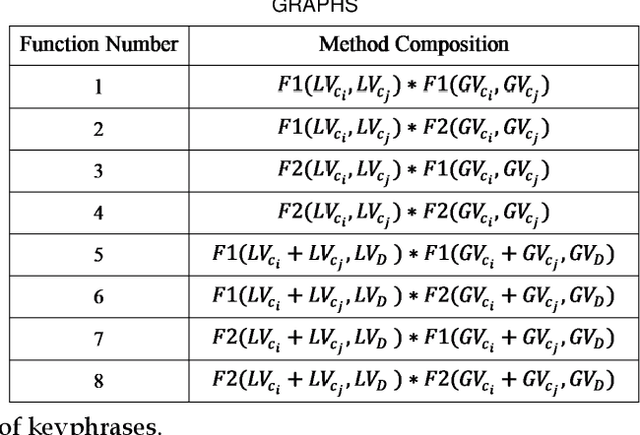
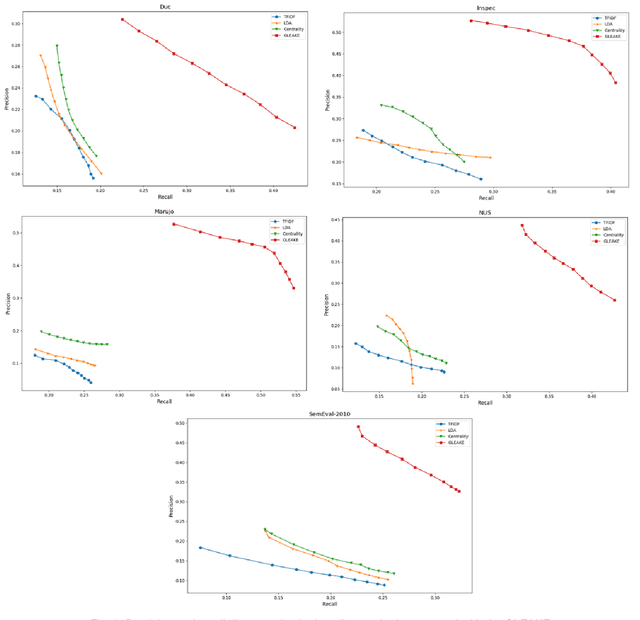
Automated methods for granular categorization of large corpora of text documents have become increasingly more important with the rate scientific, news, medical, and web documents are growing in the last few years. Automatic keyphrase extraction (AKE) aims to automatically detect a small set of single or multi-words from within a single textual document that captures the main topics of the document. AKE plays an important role in various NLP and information retrieval tasks such as document summarization and categorization, full-text indexing, and article recommendation. Due to the lack of sufficient human-labeled data in different textual contents, supervised learning approaches are not ideal for automatic detection of keyphrases from the content of textual bodies. With the state-of-the-art advances in text embedding techniques, NLP researchers have focused on developing unsupervised methods to obtain meaningful insights from raw datasets. In this work, we introduce Global and Local Embedding Automatic Keyphrase Extractor (GLEAKE) for the task of AKE. GLEAKE utilizes single and multi-word embedding techniques to explore the syntactic and semantic aspects of the candidate phrases and then combines them into a series of embedding-based graphs. Moreover, GLEAKE applies network analysis techniques on each embedding-based graph to refine the most significant phrases as a final set of keyphrases. We demonstrate the high performance of GLEAKE by evaluating its results on five standard AKE datasets from different domains and writing styles and by showing its superiority with regards to other state-of-the-art methods.