 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBilateral Cross-Modality Graph Matching Attention for Feature Fusion in Visual Question Answering
Paper and Code
Dec 14, 2021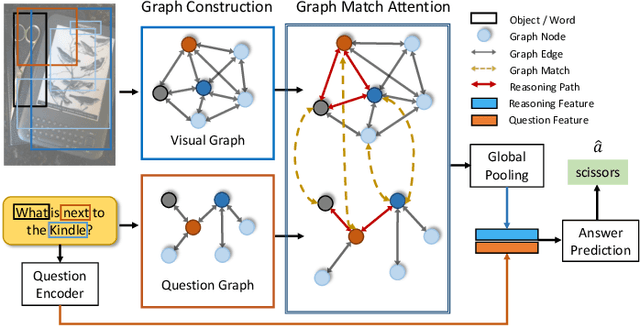
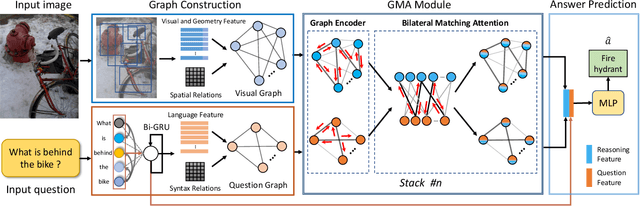
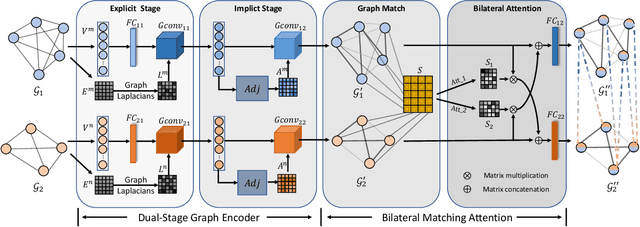
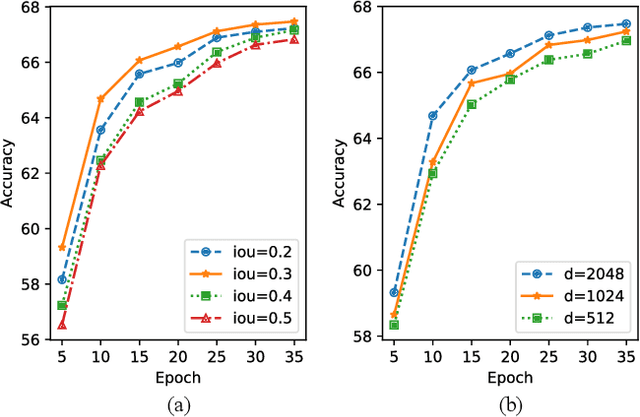
Answering semantically-complicated questions according to an image is challenging in Visual Question Answering (VQA) task. Although the image can be well represented by deep learning, the question is always simply embedded and cannot well indicate its meaning. Besides, the visual and textual features have a gap for different modalities, it is difficult to align and utilize the cross-modality information. In this paper, we focus on these two problems and propose a Graph Matching Attention (GMA) network. Firstly, it not only builds graph for the image, but also constructs graph for the question in terms of both syntactic and embedding information. Next, we explore the intra-modality relationships by a dual-stage graph encoder and then present a bilateral cross-modality graph matching attention to infer the relationships between the image and the question. The updated cross-modality features are then sent into the answer prediction module for final answer prediction. Experiments demonstrate that our network achieves state-of-the-art performance on the GQA dataset and the VQA 2.0 dataset. The ablation studies verify the effectiveness of each modules in our GMA network.