 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLDACP: Long-Delayed Ad Conversions Prediction Model for Bidding Strategy
Nov 25, 2024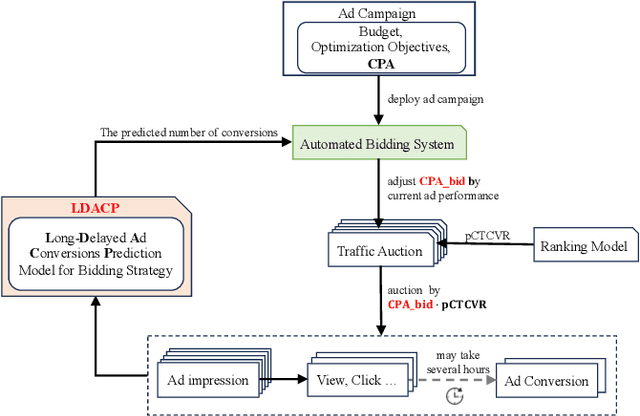

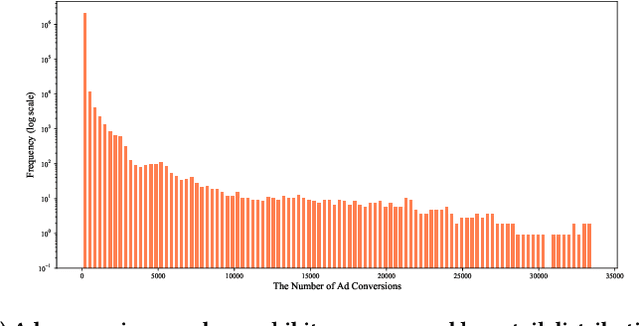

In online advertising, once an ad campaign is deployed, the automated bidding system dynamically adjusts the bidding strategy to optimize Cost Per Action (CPA) based on the number of ad conversions. For ads with a long conversion delay, relying solely on the real-time tracked conversion number as a signal for bidding strategy can significantly overestimate the current CPA, leading to conservative bidding strategies. Therefore, it is crucial to predict the number of long-delayed conversions. Nonetheless, it is challenging to predict ad conversion numbers through traditional regression methods due to the wide range of ad conversion numbers. Previous regression works have addressed this challenge by transforming regression problems into bucket classification problems, achieving success in various scenarios. However, specific challenges arise when predicting the number of ad conversions: 1) The integer nature of ad conversion numbers exacerbates the discontinuity issue in one-hot hard labels; 2) The long-tail distribution of ad conversion numbers complicates tail data prediction. In this paper, we propose the Long-Delayed Ad Conversions Prediction model for bidding strategy (LDACP), which consists of two sub-modules. To alleviate the issue of discontinuity in one-hot hard labels, the Bucket Classification Module with label Smoothing method (BCMS) converts one-hot hard labels into non-normalized soft labels, then fits these soft labels by minimizing classification loss and regression loss. To address the challenge of predicting tail data, the Value Regression Module with Proxy labels (VRMP) uses the prediction bias of aggregated pCTCVR as proxy labels. Finally, a Mixture of Experts (MoE) structure integrates the predictions from BCMS and VRMP to obtain the final predicted ad conversion number.
Online Vectorized HD Map Construction using Geometry
Dec 06, 2023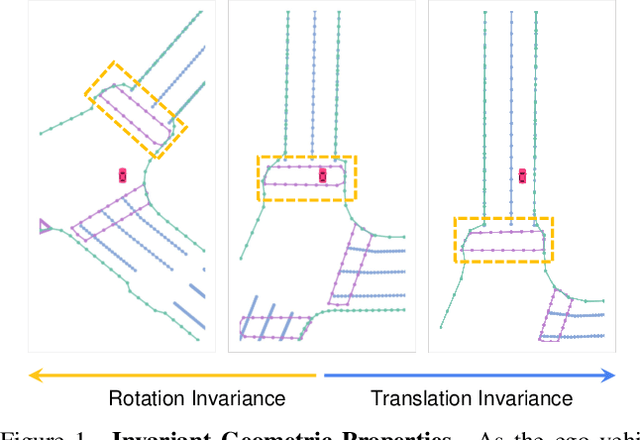
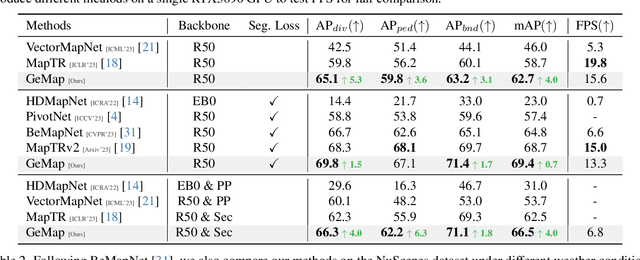
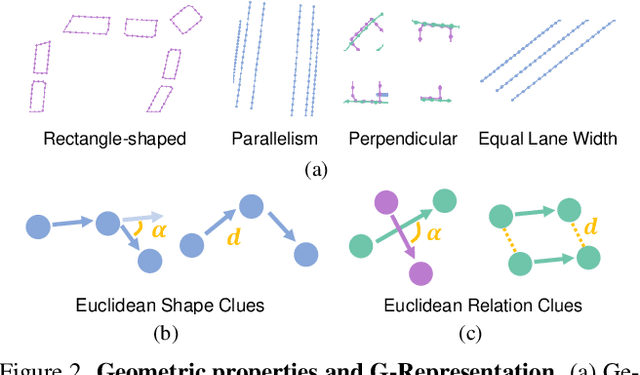

The construction of online vectorized High-Definition (HD) maps is critical for downstream prediction and planning. Recent efforts have built strong baselines for this task, however, shapes and relations of instances in urban road systems are still under-explored, such as parallelism, perpendicular, or rectangle-shape. In our work, we propose GeMap ($\textbf{Ge}$ometry $\textbf{Map}$), which end-to-end learns Euclidean shapes and relations of map instances beyond basic perception. Specifically, we design a geometric loss based on angle and distance clues, which is robust to rigid transformations. We also decouple self-attention to independently handle Euclidean shapes and relations. Our method achieves new state-of-the-art performance on the NuScenes and Argoverse 2 datasets. Remarkably, it reaches a 71.8% mAP on the large-scale Argoverse 2 dataset, outperforming MapTR V2 by +4.4% and surpassing the 70% mAP threshold for the first time. Code is available at https://github.com/cnzzx/GeMap
Locally Differentially Private Graph Embedding
Oct 17, 2023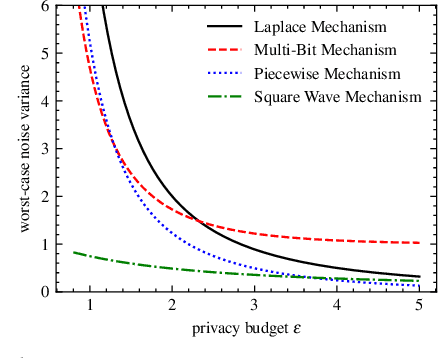



Graph embedding has been demonstrated to be a powerful tool for learning latent representations for nodes in a graph. However, despite its superior performance in various graph-based machine learning tasks, learning over graphs can raise significant privacy concerns when graph data involves sensitive information. To address this, in this paper, we investigate the problem of developing graph embedding algorithms that satisfy local differential privacy (LDP). We propose LDP-GE, a novel privacy-preserving graph embedding framework, to protect the privacy of node data. Specifically, we propose an LDP mechanism to obfuscate node data and adopt personalized PageRank as the proximity measure to learn node representations. Then, we theoretically analyze the privacy guarantees and utility of the LDP-GE framework. Extensive experiments conducted over several real-world graph datasets demonstrate that LDP-GE achieves favorable privacy-utility trade-offs and significantly outperforms existing approaches in both node classification and link prediction tasks.
Fine-Grained and High-Faithfulness Explanations for Convolutional Neural Networks
Mar 16, 2023



Recently, explaining CNNs has become a research hotspot. CAM (Class Activation Map)-based methods and LRP (Layer-wise Relevance Propagation) method are two common explanation methods. However, due to the small spatial resolution of the last convolutional layer, the CAM-based methods can often only generate coarse-grained visual explanations that provide a coarse location of the target object. LRP and its variants, on the other hand, can generate fine-grained explanations. But the faithfulness of the explanations is too low. In this paper, we propose FG-CAM (fine-grained CAM), which extends the CAM-based methods to generate fine-grained visual explanations with high faithfulness. FG-CAM uses the relationship between two adjacent layers of feature maps with resolution difference to gradually increase the explanation resolution, while finding the contributing pixels and filtering out the pixels that do not contribute at each step. Our method not only solves the shortcoming of CAM-based methods without changing their characteristics, but also generates fine-grained explanations that have higher faithfulness than LRP and its variants. We also present FG-CAM with denoising, which is a variant of FG-CAM and is able to generate less noisy explanations with almost no change in explanation faithfulness. Experimental results show that the performance of FG-CAM is almost unaffected by the explanation resolution. FG-CAM outperforms existing CAM-based methods significantly in the both shallow and intermediate convolutional layers, and outperforms LRP and its variations significantly in the input layer.