 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQARM: Quantitative Alignment Multi-Modal Recommendation at Kuaishou
Nov 18, 2024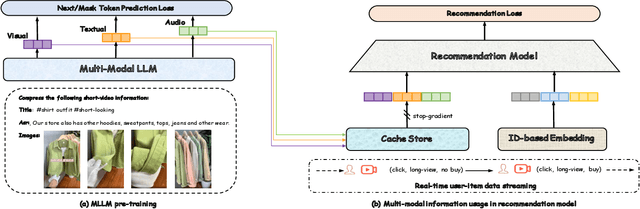
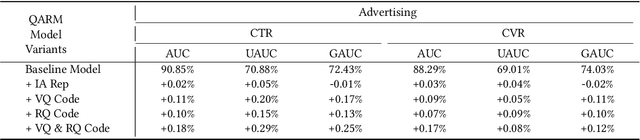
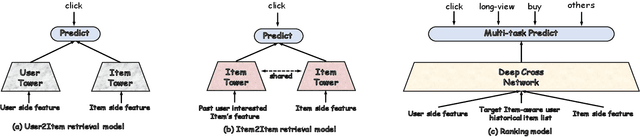
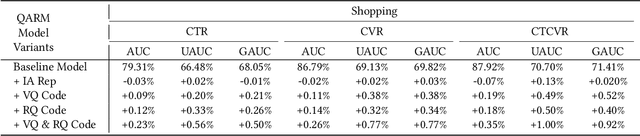
In recent years, with the significant evolution of multi-modal large models, many recommender researchers realized the potential of multi-modal information for user interest modeling. In industry, a wide-used modeling architecture is a cascading paradigm: (1) first pre-training a multi-modal model to provide omnipotent representations for downstream services; (2) The downstream recommendation model takes the multi-modal representation as additional input to fit real user-item behaviours. Although such paradigm achieves remarkable improvements, however, there still exist two problems that limit model performance: (1) Representation Unmatching: The pre-trained multi-modal model is always supervised by the classic NLP/CV tasks, while the recommendation models are supervised by real user-item interaction. As a result, the two fundamentally different tasks' goals were relatively separate, and there was a lack of consistent objective on their representations; (2) Representation Unlearning: The generated multi-modal representations are always stored in cache store and serve as extra fixed input of recommendation model, thus could not be updated by recommendation model gradient, further unfriendly for downstream training. Inspired by the two difficulties challenges in downstream tasks usage, we introduce a quantitative multi-modal framework to customize the specialized and trainable multi-modal information for different downstream models.
Fine-Grained and High-Faithfulness Explanations for Convolutional Neural Networks
Mar 16, 2023



Recently, explaining CNNs has become a research hotspot. CAM (Class Activation Map)-based methods and LRP (Layer-wise Relevance Propagation) method are two common explanation methods. However, due to the small spatial resolution of the last convolutional layer, the CAM-based methods can often only generate coarse-grained visual explanations that provide a coarse location of the target object. LRP and its variants, on the other hand, can generate fine-grained explanations. But the faithfulness of the explanations is too low. In this paper, we propose FG-CAM (fine-grained CAM), which extends the CAM-based methods to generate fine-grained visual explanations with high faithfulness. FG-CAM uses the relationship between two adjacent layers of feature maps with resolution difference to gradually increase the explanation resolution, while finding the contributing pixels and filtering out the pixels that do not contribute at each step. Our method not only solves the shortcoming of CAM-based methods without changing their characteristics, but also generates fine-grained explanations that have higher faithfulness than LRP and its variants. We also present FG-CAM with denoising, which is a variant of FG-CAM and is able to generate less noisy explanations with almost no change in explanation faithfulness. Experimental results show that the performance of FG-CAM is almost unaffected by the explanation resolution. FG-CAM outperforms existing CAM-based methods significantly in the both shallow and intermediate convolutional layers, and outperforms LRP and its variations significantly in the input layer.