 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInsPro: Propagating Instance Query and Proposal for Online Video Instance Segmentation
Jan 05, 2023Video instance segmentation (VIS) aims at segmenting and tracking objects in videos. Prior methods typically generate frame-level or clip-level object instances first and then associate them by either additional tracking heads or complex instance matching algorithms. This explicit instance association approach increases system complexity and fails to fully exploit temporal cues in videos. In this paper, we design a simple, fast and yet effective query-based framework for online VIS. Relying on an instance query and proposal propagation mechanism with several specially developed components, this framework can perform accurate instance association implicitly. Specifically, we generate frame-level object instances based on a set of instance query-proposal pairs propagated from previous frames. This instance query-proposal pair is learned to bind with one specific object across frames through conscientiously developed strategies. When using such a pair to predict an object instance on the current frame, not only the generated instance is automatically associated with its precursors on previous frames, but the model gets a good prior for predicting the same object. In this way, we naturally achieve implicit instance association in parallel with segmentation and elegantly take advantage of temporal clues in videos. To show the effectiveness of our method InsPro, we evaluate it on two popular VIS benchmarks, i.e., YouTube-VIS 2019 and YouTube-VIS 2021. Without bells-and-whistles, our InsPro with ResNet-50 backbone achieves 43.2 AP and 37.6 AP on these two benchmarks respectively, outperforming all other online VIS methods.
PanopticDepth: A Unified Framework for Depth-aware Panoptic Segmentation
Jun 01, 2022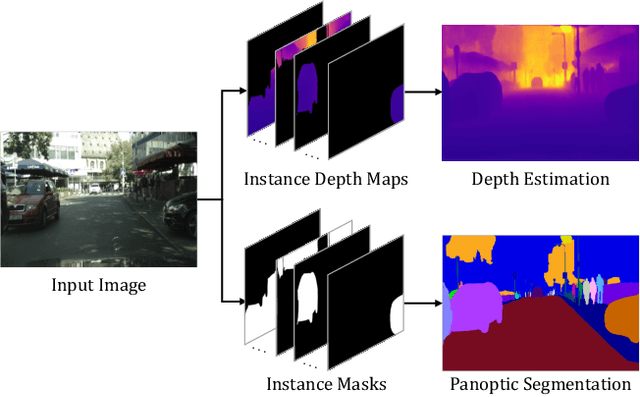
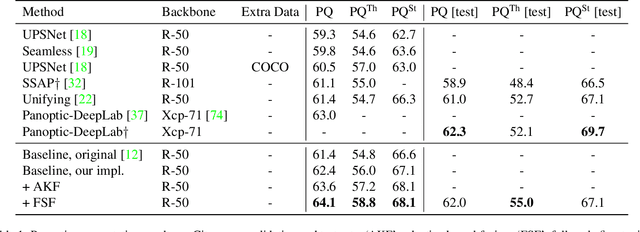
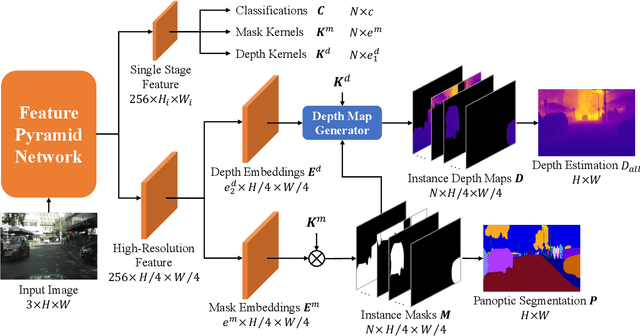

This paper presents a unified framework for depth-aware panoptic segmentation (DPS), which aims to reconstruct 3D scene with instance-level semantics from one single image. Prior works address this problem by simply adding a dense depth regression head to panoptic segmentation (PS) networks, resulting in two independent task branches. This neglects the mutually-beneficial relations between these two tasks, thus failing to exploit handy instance-level semantic cues to boost depth accuracy while also producing sub-optimal depth maps. To overcome these limitations, we propose a unified framework for the DPS task by applying a dynamic convolution technique to both the PS and depth prediction tasks. Specifically, instead of predicting depth for all pixels at a time, we generate instance-specific kernels to predict depth and segmentation masks for each instance. Moreover, leveraging the instance-wise depth estimation scheme, we add additional instance-level depth cues to assist with supervising the depth learning via a new depth loss. Extensive experiments on Cityscapes-DPS and SemKITTI-DPS show the effectiveness and promise of our method. We hope our unified solution to DPS can lead a new paradigm in this area. Code is available at https://github.com/NaiyuGao/PanopticDepth.
Learning Category- and Instance-Aware Pixel Embedding for Fast Panoptic Segmentation
Sep 28, 2020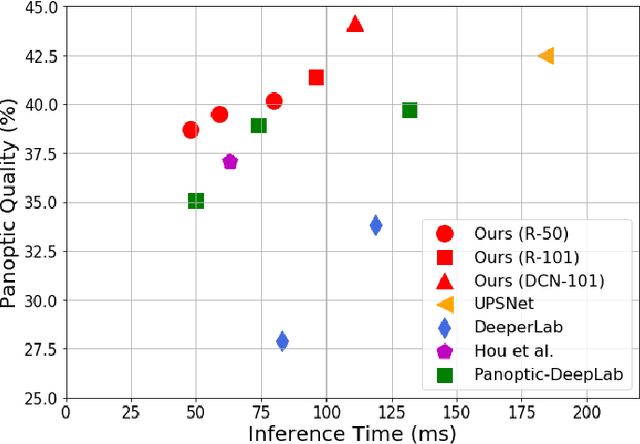
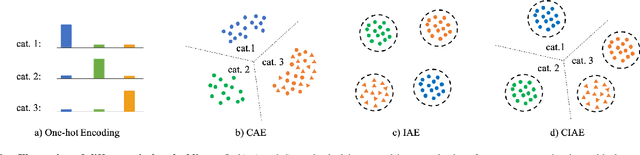
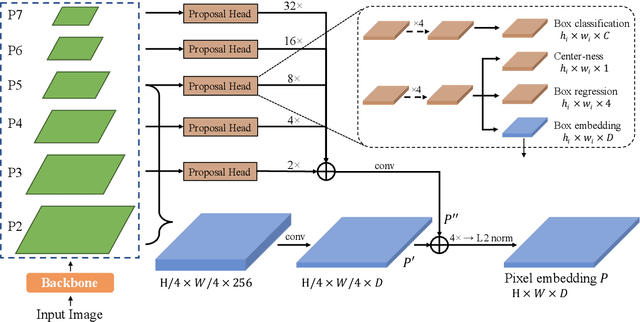
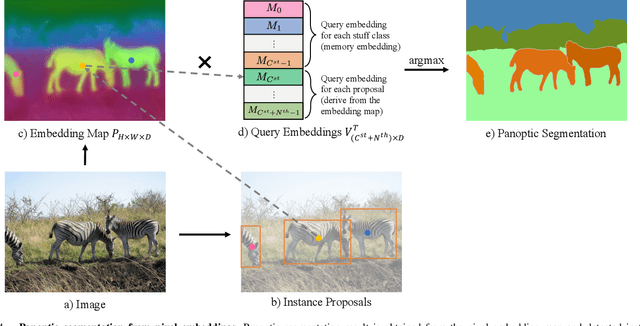
Panoptic segmentation (PS) is a complex scene understanding task that requires providing high-quality segmentation for both thing objects and stuff regions. Previous methods handle these two classes with semantic and instance segmentation modules separately, following with heuristic fusion or additional modules to resolve the conflicts between the two outputs. This work simplifies this pipeline of PS by consistently modeling the two classes with a novel PS framework, which extends a detection model with an extra module to predict category- and instance-aware pixel embedding (CIAE). CIAE is a novel pixel-wise embedding feature that encodes both semantic-classification and instance-distinction information. At the inference process, PS results are simply derived by assigning each pixel to a detected instance or a stuff class according to the learned embedding. Our method not only shows fast inference speed but also the first one-stage method to achieve comparable performance to two-stage methods on the challenging COCO benchmark.
SSAP: Single-Shot Instance Segmentation With Affinity Pyramid
Sep 04, 2019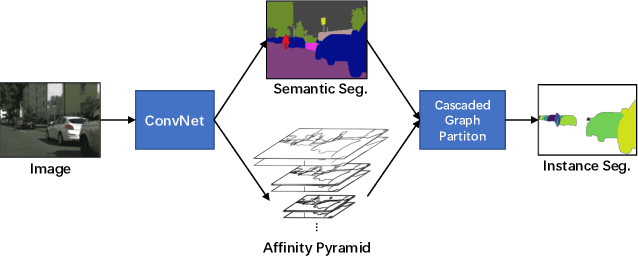

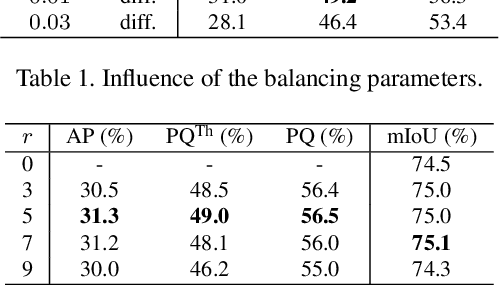
Recently, proposal-free instance segmentation has received increasing attention due to its concise and efficient pipeline. Generally, proposal-free methods generate instance-agnostic semantic segmentation labels and instance-aware features to group pixels into different object instances. However, previous methods mostly employ separate modules for these two sub-tasks and require multiple passes for inference. We argue that treating these two sub-tasks separately is suboptimal. In fact, employing multiple separate modules significantly reduces the potential for application. The mutual benefits between the two complementary sub-tasks are also unexplored. To this end, this work proposes a single-shot proposal-free instance segmentation method that requires only one single pass for prediction. Our method is based on a pixel-pair affinity pyramid, which computes the probability that two pixels belong to the same instance in a hierarchical manner. The affinity pyramid can also be jointly learned with the semantic class labeling and achieve mutual benefits. Moreover, incorporating with the learned affinity pyramid, a novel cascaded graph partition module is presented to sequentially generate instances from coarse to fine. Unlike previous time-consuming graph partition methods, this module achieves $5\times$ speedup and 9% relative improvement on Average-Precision (AP). Our approach achieves state-of-the-art results on the challenging Cityscapes dataset.
Bi-Directional Cascade Network for Perceptual Edge Detection
Feb 28, 2019
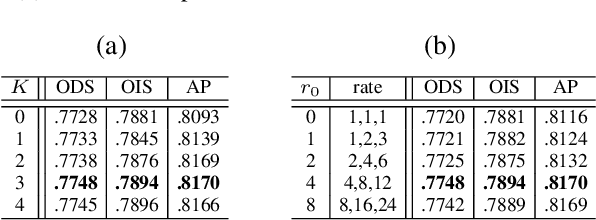
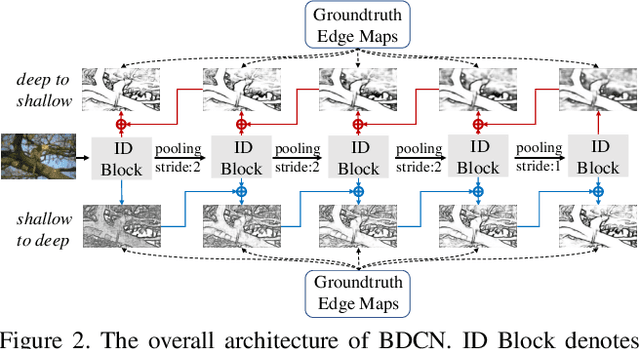
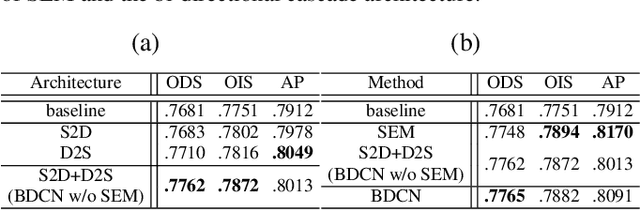
Exploiting multi-scale representations is critical to improve edge detection for objects at different scales. To extract edges at dramatically different scales, we propose a Bi-Directional Cascade Network (BDCN) structure, where an individual layer is supervised by labeled edges at its specific scale, rather than directly applying the same supervision to all CNN outputs. Furthermore, to enrich multi-scale representations learned by BDCN, we introduce a Scale Enhancement Module (SEM) which utilizes dilated convolution to generate multi-scale features, instead of using deeper CNNs or explicitly fusing multi-scale edge maps. These new approaches encourage the learning of multi-scale representations in different layers and detect edges that are well delineated by their scales. Learning scale dedicated layers also results in compact network with a fraction of parameters. We evaluate our method on three datasets, i.e., BSDS500, NYUDv2, and Multicue, and achieve ODS Fmeasure of 0.828, 1.3% higher than current state-of-the art on BSDS500. The code has been available at https://github.com/pkuCactus/BDCN.