 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASR-enhanced Multimodal Representation Learning for Cross-Domain Product Retrieval
Paper and Code
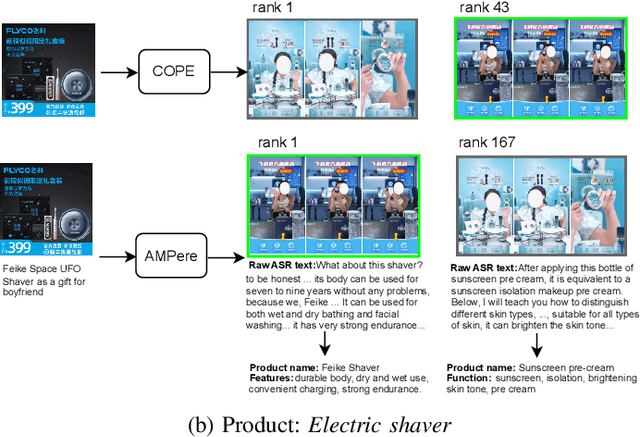
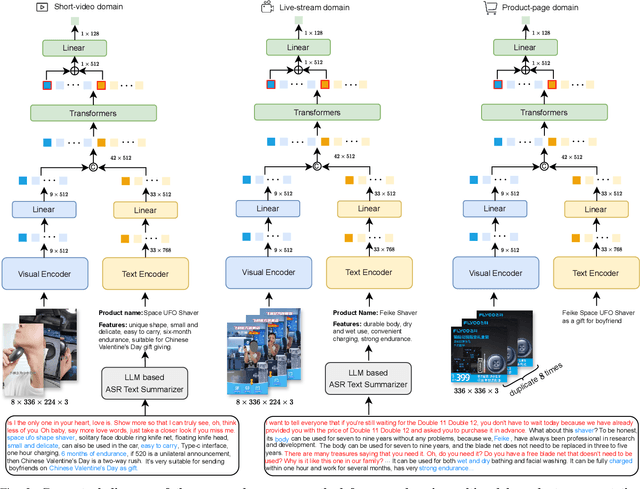

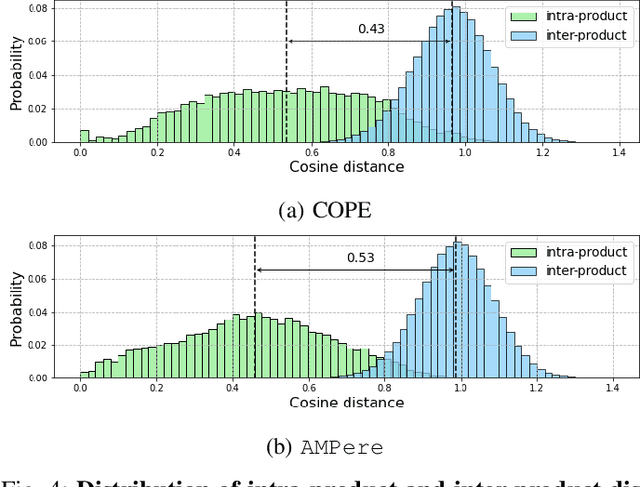
E-commerce is increasingly multimedia-enriched, with products exhibited in a broad-domain manner as images, short videos, or live stream promotions. A unified and vectorized cross-domain production representation is essential. Due to large intra-product variance and high inter-product similarity in the broad-domain scenario, a visual-only representation is inadequate. While Automatic Speech Recognition (ASR) text derived from the short or live-stream videos is readily accessible, how to de-noise the excessively noisy text for multimodal representation learning is mostly untouched. We propose ASR-enhanced Multimodal Product Representation Learning (AMPere). In order to extract product-specific information from the raw ASR text, AMPere uses an easy-to-implement LLM-based ASR text summarizer. The LLM-summarized text, together with visual data, is then fed into a multi-branch network to generate compact multimodal embeddings. Extensive experiments on a large-scale tri-domain dataset verify the effectiveness of AMPere in obtaining a unified multimodal product representation that clearly improves cross-domain product retrieval.