 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Optimal Customized Architecture for Heterogeneous Federated Learning with Contrastive Cloud-Edge Model Decoupling
Mar 04, 2024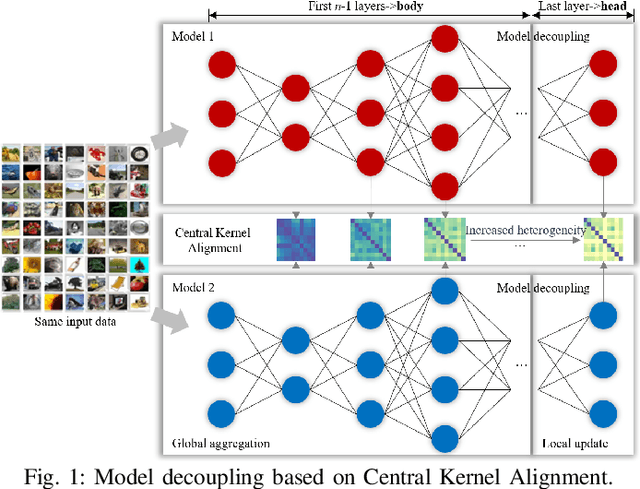
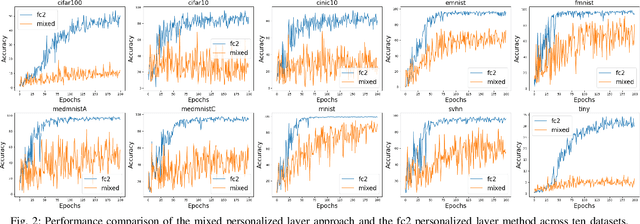
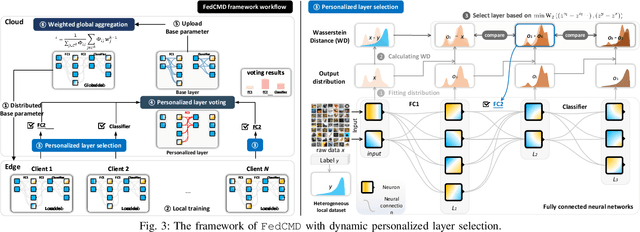
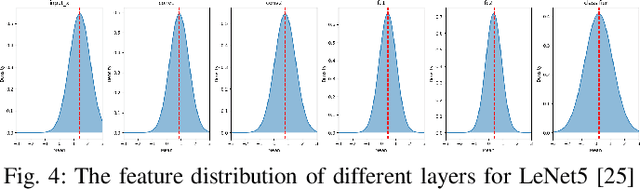
Federated learning, as a promising distributed learning paradigm, enables collaborative training of a global model across multiple network edge clients without the need for central data collecting. However, the heterogeneity of edge data distribution drags the model towards the local minima, which can be distant from the global optimum. Such heterogeneity often leads to slow convergence and substantial communication overhead. To address these issues, we propose a novel federated learning framework called FedCMD, a model decoupling tailored to the Cloud-edge supported federated learning that separates deep neural networks into a body for capturing shared representations in Cloud and a personalized head for migrating data heterogeneity. Our motivation is that, by the deep investigation of the performance of selecting different neural network layers as the personalized head, we found rigidly assigning the last layer as the personalized head in current studies is not always optimal. Instead, it is necessary to dynamically select the personalized layer that maximizes the training performance by taking the representation difference between neighbor layers into account. To find the optimal personalized layer, we utilize the low-dimensional representation of each layer to contrast feature distribution transfer and introduce a Wasserstein-based layer selection method, aimed at identifying the best-match layer for personalization. Additionally, a weighted global aggregation algorithm is proposed based on the selected personalized layer for the practical application of FedCMD. Extensive experiments on ten benchmarks demonstrate the efficiency and superior performance of our solution compared with nine state-of-the-art solutions. All code and results are available at https://github.com/elegy112138/FedCMD.
Taming Gradient Variance in Federated Learning with Networked Control Variates
Oct 26, 2023Federated learning, a decentralized approach to machine learning, faces significant challenges such as extensive communication overheads, slow convergence, and unstable improvements. These challenges primarily stem from the gradient variance due to heterogeneous client data distributions. To address this, we introduce a novel Networked Control Variates (FedNCV) framework for Federated Learning. We adopt the REINFORCE Leave-One-Out (RLOO) as a fundamental control variate unit in the FedNCV framework, implemented at both client and server levels. At the client level, the RLOO control variate is employed to optimize local gradient updates, mitigating the variance introduced by data samples. Once relayed to the server, the RLOO-based estimator further provides an unbiased and low-variance aggregated gradient, leading to robust global updates. This dual-side application is formalized as a linear combination of composite control variates. We provide a mathematical expression capturing this integration of double control variates within FedNCV and present three theoretical results with corresponding proofs. This unique dual structure equips FedNCV to address data heterogeneity and scalability issues, thus potentially paving the way for large-scale applications. Moreover, we tested FedNCV on six diverse datasets under a Dirichlet distribution with {\alpha} = 0.1, and benchmarked its performance against six SOTA methods, demonstrating its superiority.
Noise Robust TTS for Low Resource Speakers using Pre-trained Model and Speech Enhancement
May 26, 2020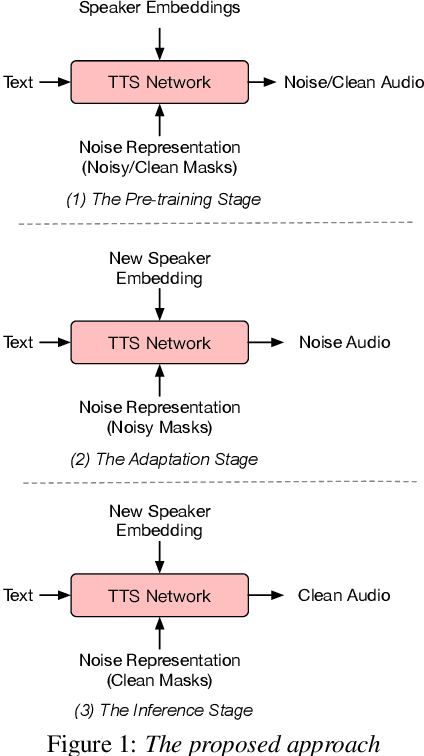
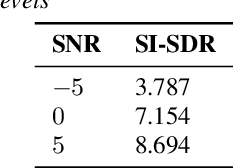
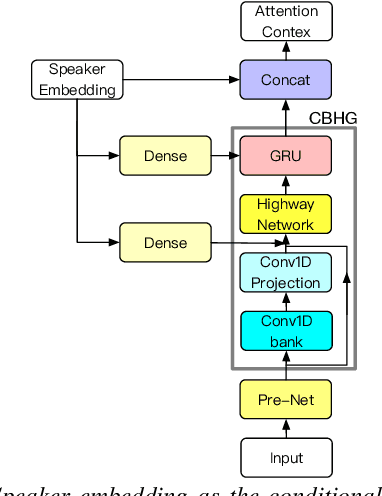
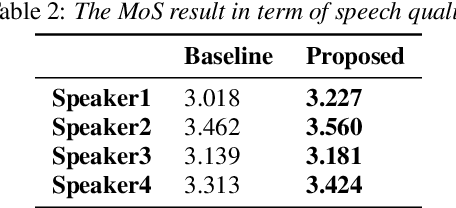
With the popularity of deep neural network, speech synthesis task has achieved significant improvements based on the end-to-end encoder-decoder framework in the recent days. More and more applications relying on speech synthesis technology have been widely used in our daily life. Robust speech synthesis model depends on high quality and customized data which needs lots of collecting efforts. It is worth investigating how to take advantage of low-quality and low resource voice data which can be easily obtained from the Internet for usage of synthesizing personalized voice. In this paper, the proposed end-to-end speech synthesis model uses both speaker embedding and noise representation as conditional inputs to model speaker and noise information respectively. Firstly, the speech synthesis model is pre-trained with both multi-speaker clean data and noisy augmented data; then the pre-trained model is adapted on noisy low-resource new speaker data; finally, by setting the clean speech condition, the model can synthesize the new speaker's clean voice. Experimental results show that the speech generated by the proposed approach has better subjective evaluation results than the method directly fine-tuning pre-trained multi-speaker speech synthesis model with denoised new speaker data.