 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise Robust TTS for Low Resource Speakers using Pre-trained Model and Speech Enhancement
Paper and Code
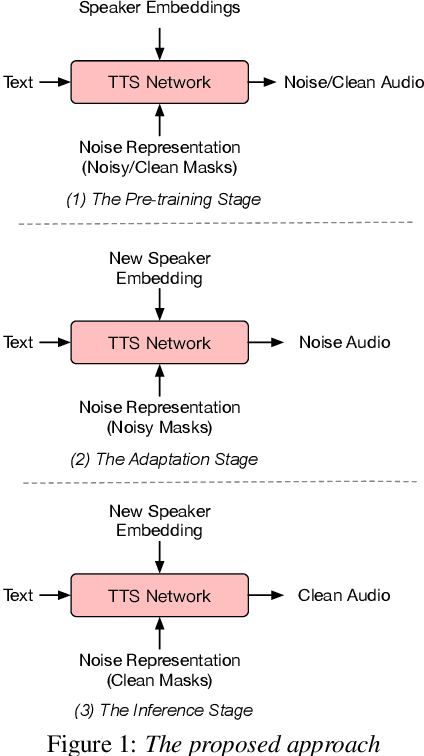
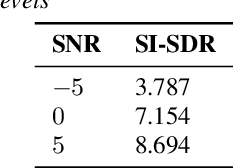
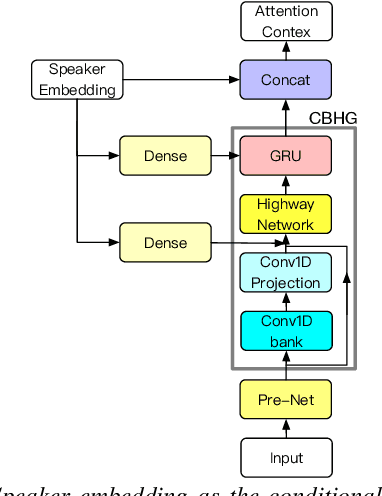
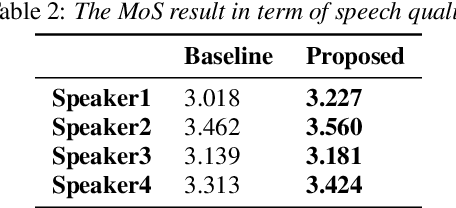
With the popularity of deep neural network, speech synthesis task has achieved significant improvements based on the end-to-end encoder-decoder framework in the recent days. More and more applications relying on speech synthesis technology have been widely used in our daily life. Robust speech synthesis model depends on high quality and customized data which needs lots of collecting efforts. It is worth investigating how to take advantage of low-quality and low resource voice data which can be easily obtained from the Internet for usage of synthesizing personalized voice. In this paper, the proposed end-to-end speech synthesis model uses both speaker embedding and noise representation as conditional inputs to model speaker and noise information respectively. Firstly, the speech synthesis model is pre-trained with both multi-speaker clean data and noisy augmented data; then the pre-trained model is adapted on noisy low-resource new speaker data; finally, by setting the clean speech condition, the model can synthesize the new speaker's clean voice. Experimental results show that the speech generated by the proposed approach has better subjective evaluation results than the method directly fine-tuning pre-trained multi-speaker speech synthesis model with denoised new speaker data.