 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAGE: Multi-Agent Self-Evolution for LLM Reasoning
Mar 17, 2026Reinforcement learning with verifiable rewards improves reasoning in large language models (LLMs), but many methods still rely on large human-labeled datasets. While self-play reduces this dependency, it often lacks explicit planning and strong quality control, limiting stability in long-horizon multi-step reasoning. We present SAGE (Self-evolving Agents for Generalized reasoning Evolution), a closed-loop framework where four agents: Challenger, Planner, Solver, and Critic, co-evolve from a shared LLM backbone using only a small seed set. The Challenger continuously generates increasingly difficult tasks; the Planner converts each task into a structured multi-step plan; and the Solver follows the plan to produce an answer, whose correctness is determined by external verifiers. The Critic scores and filters both generated questions and plans to prevent curriculum drift and maintain training signal quality, enabling stable self-training. Across mathematics and code-generation benchmarks, SAGE delivers consistent gains across model scales, improving the Qwen-2.5-7B model by 8.9% on LiveCodeBench and 10.7% on OlympiadBench.
ForeDiffusion: Foresight-Conditioned Diffusion Policy via Future View Construction for Robot Manipulation
Jan 19, 2026Diffusion strategies have advanced visual motor control by progressively denoising high-dimensional action sequences, providing a promising method for robot manipulation. However, as task complexity increases, the success rate of existing baseline models decreases considerably. Analysis indicates that current diffusion strategies are confronted with two limitations. First, these strategies only rely on short-term observations as conditions. Second, the training objective remains limited to a single denoising loss, which leads to error accumulation and causes grasping deviations. To address these limitations, this paper proposes Foresight-Conditioned Diffusion (ForeDiffusion), by injecting the predicted future view representation into the diffusion process. As a result, the policy is guided to be forward-looking, enabling it to correct trajectory deviations. Following this design, ForeDiffusion employs a dual loss mechanism, combining the traditional denoising loss and the consistency loss of future observations, to achieve the unified optimization. Extensive evaluation on the Adroit suite and the MetaWorld benchmark demonstrates that ForeDiffusion achieves an average success rate of 80% for the overall task, significantly outperforming the existing mainstream diffusion methods by 23% in complex tasks, while maintaining more stable performance across the entire tasks.
Solution for CVPR 2024 UG2+ Challenge Track on All Weather Semantic Segmentation
Jun 09, 2024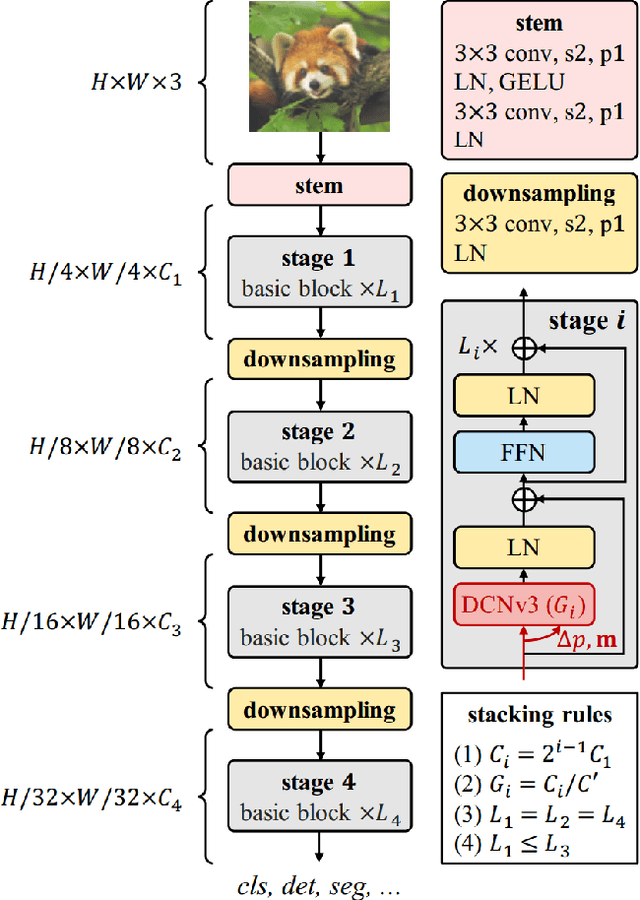
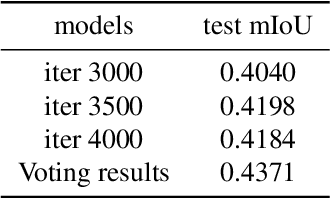

In this report, we present our solution for the semantic segmentation in adverse weather, in UG2+ Challenge at CVPR 2024. To achieve robust and accurate segmentation results across various weather conditions, we initialize the InternImage-H backbone with pre-trained weights from the large-scale joint dataset and enhance it with the state-of-the-art Upernet segmentation method. Specifically, we utilize offline and online data augmentation approaches to extend the train set, which helps us to further improve the performance of the segmenter. As a result, our proposed solution demonstrates advanced performance on the test set and achieves 3rd position in this challenge.
RRWKV: Capturing Long-range Dependencies in RWKV
Jun 09, 2023Owing to the impressive dot-product attention, the Transformers have been the dominant architectures in various natural language processing (NLP) tasks. Recently, the Receptance Weighted Key Value (RWKV) architecture follows a non-transformer architecture to eliminate the drawbacks of dot-product attention, where memory and computational complexity exhibits quadratic scaling with sequence length. Although RWKV has exploited a linearly tensor-product attention mechanism and achieved parallelized computations by deploying the time-sequential mode, it fails to capture long-range dependencies because of its limitation on looking back at previous information, compared with full information obtained by direct interactions in the standard transformer. Therefore, the paper devises the Retrospected Receptance Weighted Key Value (RRWKV) architecture via incorporating the retrospecting ability into the RWKV to effectively absorb information, which maintains memory and computational efficiency as well.
AWTE-BERT:Attending to Wordpiece Tokenization Explicitly on BERT for Joint Intent Classification and SlotFilling
Nov 29, 2022



Intent classification and slot filling are two core tasks in natural language understanding (NLU). The interaction nature of the two tasks makes the joint models often outperform the single designs. One of the promising solutions, called BERT (Bidirectional Encoder Representations from Transformers), achieves the joint optimization of the two tasks. BERT adopts the wordpiece to tokenize each input token into multiple sub-tokens, which causes a mismatch between the tokens and the labels lengths. Previous methods utilize the hidden states corresponding to the first sub-token as input to the classifier, which limits performance improvement since some hidden semantic informations is discarded in the fine-tune process. To address this issue, we propose a novel joint model based on BERT, which explicitly models the multiple sub-tokens features after wordpiece tokenization, thereby generating the context features that contribute to slot filling. Specifically, we encode the hidden states corresponding to multiple sub-tokens into a context vector via the attention mechanism. Then, we feed each context vector into the slot filling encoder, which preserves the integrity of the sentence. Experimental results demonstrate that our proposed model achieves significant improvement on intent classification accuracy, slot filling F1, and sentence-level semantic frame accuracy on two public benchmark datasets. The F1 score of the slot filling in particular has been improved from 96.1 to 98.2 (2.1% absolute) on the ATIS dataset.