 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCountry-wide, high-resolution monitoring of forest browning with Sentinel-2
Apr 02, 2026Natural and anthropogenic disturbances are impacting the health of forests worldwide. Monitoring forest disturbances at scale is important to inform conservation efforts. Here, we present a scalable approach for country-wide mapping of forest greenness anomalies at the 10 m resolution of Sentinel-2. Using relevant ecological and topographical context and an established representation of the vegetation cycle, we learn a predictive quantile model of the normalised difference vegetation index (NDVI) derived from Sentinel-2 data. The resulting expected seasonal cycles are used to detect NDVI anomalies across Switzerland between April 2017 and August 2025. Goodness-of-fit evaluations show that the conditional model explains 65% of the observed variations in the median seasonal cycle. The model consistently benefits from the local context information, particularly during the green-up period. The approach produces coherent spatial anomaly patterns and enables country-wide quantification of forest browning. Case studies with independent reference data from known events illustrate that the model reliably detects different types of disturbances.
Improving Retrieval-Augmented Large Language Models via Data Importance Learning
Jul 06, 2023



Retrieval augmentation enables large language models to take advantage of external knowledge, for example on tasks like question answering and data imputation. However, the performance of such retrieval-augmented models is limited by the data quality of their underlying retrieval corpus. In this paper, we propose an algorithm based on multilinear extension for evaluating the data importance of retrieved data points. There are exponentially many terms in the multilinear extension, and one key contribution of this paper is a polynomial time algorithm that computes exactly, given a retrieval-augmented model with an additive utility function and a validation set, the data importance of data points in the retrieval corpus using the multilinear extension of the model's utility function. We further proposed an even more efficient ({\epsilon}, {\delta})-approximation algorithm. Our experimental results illustrate that we can enhance the performance of large language models by only pruning or reweighting the retrieval corpus, without requiring further training. For some tasks, this even allows a small model (e.g., GPT-JT), augmented with a search engine API, to outperform GPT-3.5 (without retrieval augmentation). Moreover, we show that weights based on multilinear extension can be computed efficiently in practice (e.g., in less than ten minutes for a corpus with 100 million elements).
Active WeaSuL: Improving Weak Supervision with Active Learning
Apr 30, 2021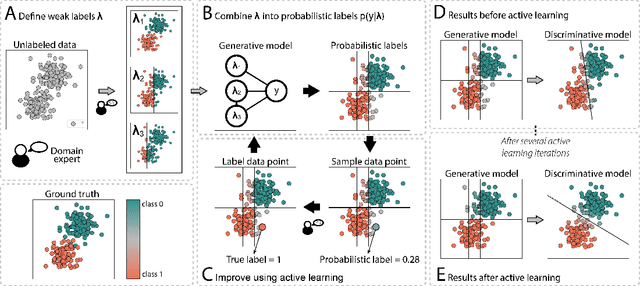

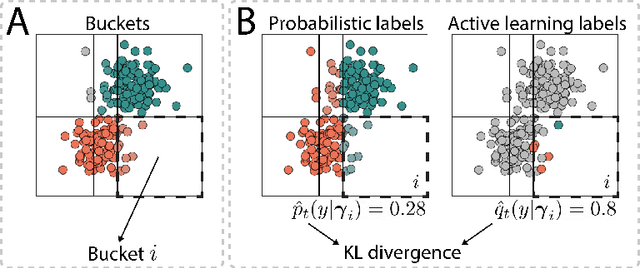
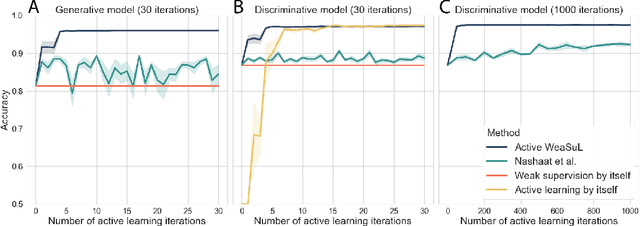
The availability of labelled data is one of the main limitations in machine learning. We can alleviate this using weak supervision: a framework that uses expert-defined rules $\boldsymbol{\lambda}$ to estimate probabilistic labels $p(y|\boldsymbol{\lambda})$ for the entire data set. These rules, however, are dependent on what experts know about the problem, and hence may be inaccurate or may fail to capture important parts of the problem-space. To mitigate this, we propose Active WeaSuL: an approach that incorporates active learning into weak supervision. In Active WeaSuL, experts do not only define rules, but they also iteratively provide the true label for a small set of points where the weak supervision model is most likely to be mistaken, which are then used to better estimate the probabilistic labels. In this way, the weak labels provide a warm start, which active learning then improves upon. We make two contributions: 1) a modification of the weak supervision loss function, such that the expert-labelled data inform and improve the combination of weak labels; and 2) the maxKL divergence sampling strategy, which determines for which data points expert labelling is most beneficial. Our experiments show that when the budget for labelling data is limited (e.g. $\leq 60$ data points), Active WeaSuL outperforms weak supervision, active learning, and competing strategies, with only a handful of labelled data points. This makes Active WeaSuL ideal for situations where obtaining labelled data is difficult.