 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive WeaSuL: Improving Weak Supervision with Active Learning
Apr 30, 2021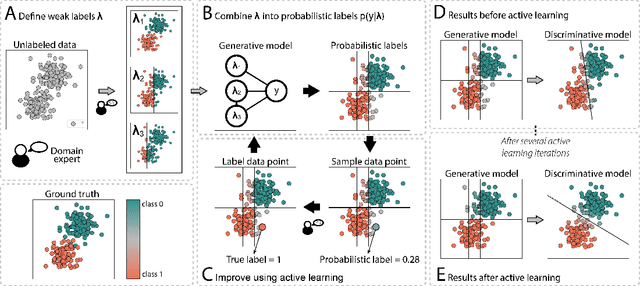

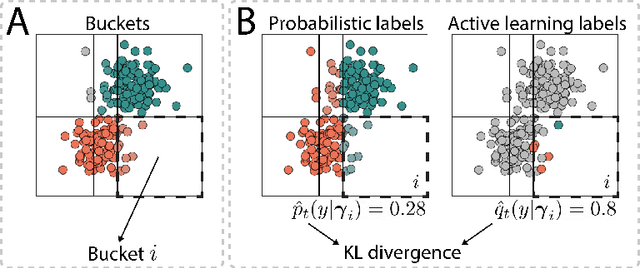
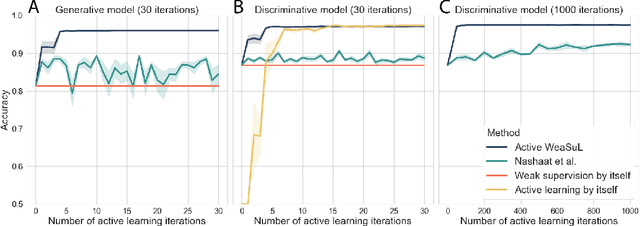
The availability of labelled data is one of the main limitations in machine learning. We can alleviate this using weak supervision: a framework that uses expert-defined rules $\boldsymbol{\lambda}$ to estimate probabilistic labels $p(y|\boldsymbol{\lambda})$ for the entire data set. These rules, however, are dependent on what experts know about the problem, and hence may be inaccurate or may fail to capture important parts of the problem-space. To mitigate this, we propose Active WeaSuL: an approach that incorporates active learning into weak supervision. In Active WeaSuL, experts do not only define rules, but they also iteratively provide the true label for a small set of points where the weak supervision model is most likely to be mistaken, which are then used to better estimate the probabilistic labels. In this way, the weak labels provide a warm start, which active learning then improves upon. We make two contributions: 1) a modification of the weak supervision loss function, such that the expert-labelled data inform and improve the combination of weak labels; and 2) the maxKL divergence sampling strategy, which determines for which data points expert labelling is most beneficial. Our experiments show that when the budget for labelling data is limited (e.g. $\leq 60$ data points), Active WeaSuL outperforms weak supervision, active learning, and competing strategies, with only a handful of labelled data points. This makes Active WeaSuL ideal for situations where obtaining labelled data is difficult.
Analysing Symbolic Regression Benchmarks under a Meta-Learning Approach
May 25, 2018



The definition of a concise and effective testbed for Genetic Programming (GP) is a recurrent matter in the research community. This paper takes a new step in this direction, proposing a different approach to measure the quality of the symbolic regression benchmarks quantitatively. The proposed approach is based on meta-learning and uses a set of dataset meta-features---such as the number of examples or output skewness---to describe the datasets. Our idea is to correlate these meta-features with the errors obtained by a GP method. These meta-features define a space of benchmarks that should, ideally, have datasets (points) covering different regions of the space. An initial analysis of 63 datasets showed that current benchmarks are concentrated in a small region of this benchmark space. We also found out that number of instances and output skewness are the most relevant meta-features to GP output error. Both conclusions can help define which datasets should compose an effective testbed for symbolic regression methods.