 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMelody Is All You Need For Music Generation
Paper and Code
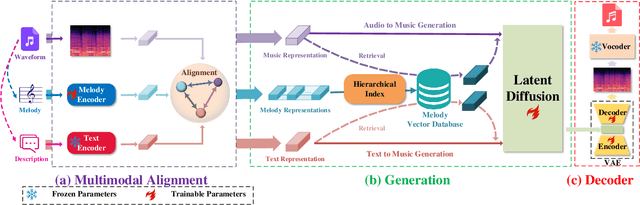
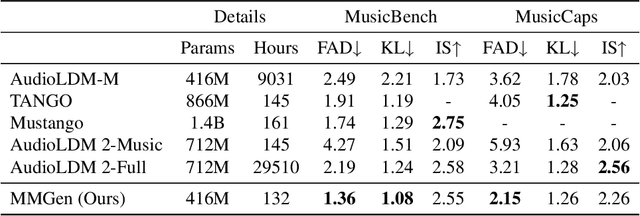
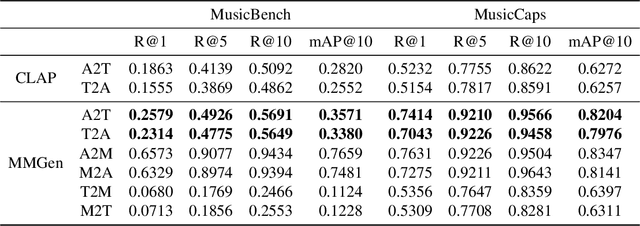
We present the Melody Guided Music Generation (MMGen) model, the first novel approach using melody to guide the music generation that, despite a pretty simple method and extremely limited resources, achieves excellent performance. Specifically, we first align the melody with audio waveforms and their associated descriptions using the multimodal alignment module. Subsequently, we condition the diffusion module on the learned melody representations. This allows MMGen to generate music that matches the style of the provided audio while also producing music that reflects the content of the given text description. To address the scarcity of high-quality data, we construct a multi-modal dataset, MusicSet, which includes melody, text, and audio, and will be made publicly available. We conduct extensive experiments which demonstrate the superiority of the proposed model both in terms of experimental metrics and actual performance quality.