 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Neural Networks with Precomputed Node Features
Paper and Code
Jun 01, 2022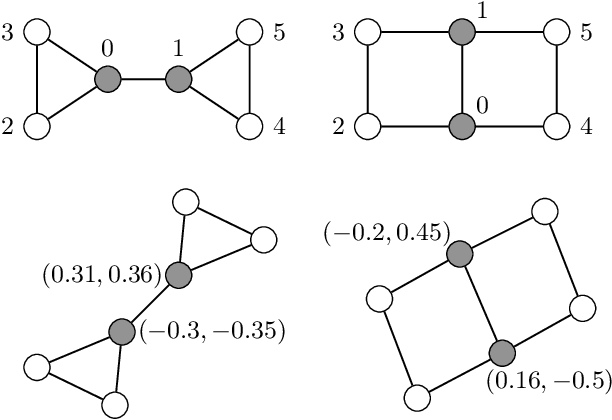
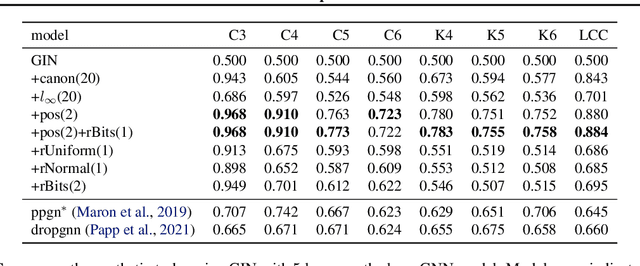
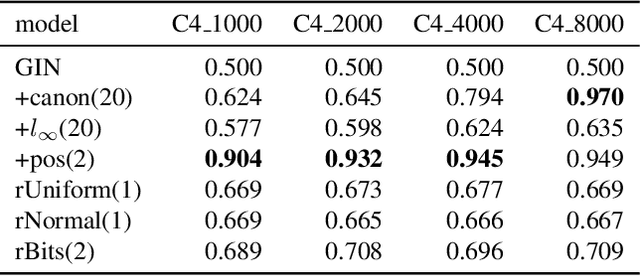
Most Graph Neural Networks (GNNs) cannot distinguish some graphs or indeed some pairs of nodes within a graph. This makes it impossible to solve certain classification tasks. However, adding additional node features to these models can resolve this problem. We introduce several such augmentations, including (i) positional node embeddings, (ii) canonical node IDs, and (iii) random features. These extensions are motivated by theoretical results and corroborated by extensive testing on synthetic subgraph detection tasks. We find that positional embeddings significantly outperform other extensions in these tasks. Moreover, positional embeddings have better sample efficiency, perform well on different graph distributions and even outperform learning with ground truth node positions. Finally, we show that the different augmentations perform competitively on established GNN benchmarks, and advise on when to use them.