 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstructing and grounding narrated instructional videos in 3D
Paper and Code
Sep 10, 2021
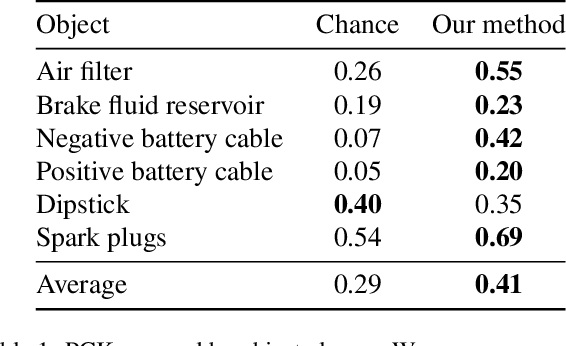
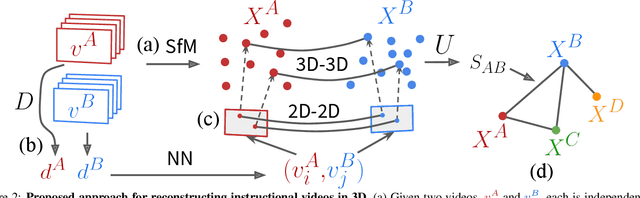

Narrated instructional videos often show and describe manipulations of similar objects, e.g., repairing a particular model of a car or laptop. In this work we aim to reconstruct such objects and to localize associated narrations in 3D. Contrary to the standard scenario of instance-level 3D reconstruction, where identical objects or scenes are present in all views, objects in different instructional videos may have large appearance variations given varying conditions and versions of the same product. Narrations may also have large variation in natural language expressions. We address these challenges by three contributions. First, we propose an approach for correspondence estimation combining learnt local features and dense flow. Second, we design a two-step divide and conquer reconstruction approach where the initial 3D reconstructions of individual videos are combined into a 3D alignment graph. Finally, we propose an unsupervised approach to ground natural language in obtained 3D reconstructions. We demonstrate the effectiveness of our approach for the domain of car maintenance. Given raw instructional videos and no manual supervision, our method successfully reconstructs engines of different car models and associates textual descriptions with corresponding objects in 3D.