 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALSTER: A Local Spatio-Temporal Expert for Online 3D Semantic Reconstruction
Dec 03, 2023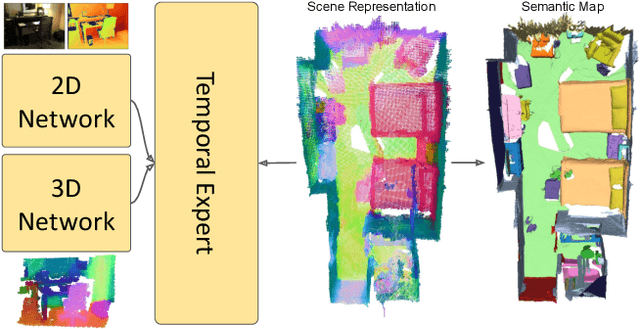
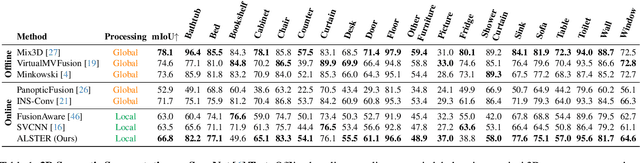
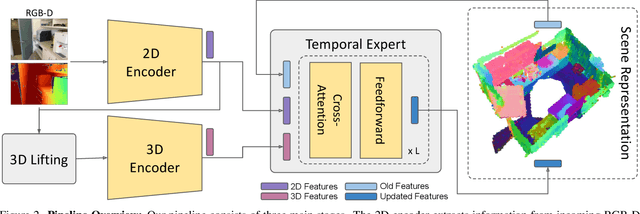
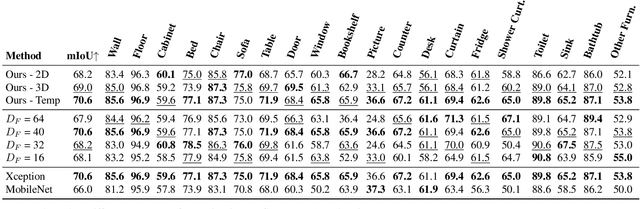
We propose an online 3D semantic segmentation method that incrementally reconstructs a 3D semantic map from a stream of RGB-D frames. Unlike offline methods, ours is directly applicable to scenarios with real-time constraints, such as robotics or mixed reality. To overcome the inherent challenges of online methods, we make two main contributions. First, to effectively extract information from the input RGB-D video stream, we jointly estimate geometry and semantic labels per frame in 3D. A key focus of our approach is to reason about semantic entities both in the 2D input and the local 3D domain to leverage differences in spatial context and network architectures. Our method predicts 2D features using an off-the-shelf segmentation network. The extracted 2D features are refined by a lightweight 3D network to enable reasoning about the local 3D structure. Second, to efficiently deal with an infinite stream of input RGB-D frames, a subsequent network serves as a temporal expert predicting the incremental scene updates by leveraging 2D, 3D, and past information in a learned manner. These updates are then integrated into a global scene representation. Using these main contributions, our method can enable scenarios with real-time constraints and can scale to arbitrary scene sizes by processing and updating the scene only in a local region defined by the new measurement. Our experiments demonstrate improved results compared to existing online methods that purely operate in local regions and show that complementary sources of information can boost the performance. We provide a thorough ablation study on the benefits of different architectural as well as algorithmic design decisions. Our method yields competitive results on the popular ScanNet benchmark and SceneNN dataset.
Quad-networks: unsupervised learning to rank for interest point detection
Apr 10, 2017
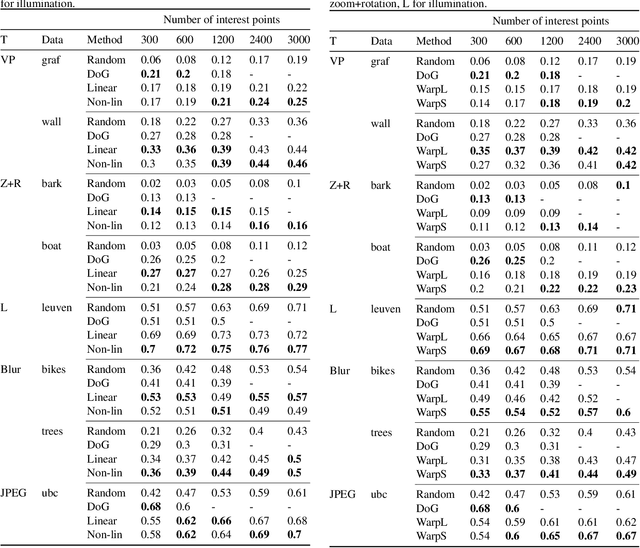
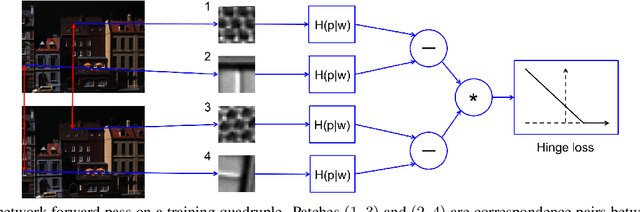

Several machine learning tasks require to represent the data using only a sparse set of interest points. An ideal detector is able to find the corresponding interest points even if the data undergo a transformation typical for a given domain. Since the task is of high practical interest in computer vision, many hand-crafted solutions were proposed. In this paper, we ask a fundamental question: can we learn such detectors from scratch? Since it is often unclear what points are "interesting", human labelling cannot be used to find a truly unbiased solution. Therefore, the task requires an unsupervised formulation. We are the first to propose such a formulation: training a neural network to rank points in a transformation-invariant manner. Interest points are then extracted from the top/bottom quantiles of this ranking. We validate our approach on two tasks: standard RGB image interest point detection and challenging cross-modal interest point detection between RGB and depth images. We quantitatively show that our unsupervised method performs better or on-par with baselines.