 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Hand Shape and Pose from Images in the Wild
Feb 09, 2019



We present in this work the first end-to-end deep learning based method that predicts both 3D hand shape and pose from RGB images in the wild. Our network consists of the concatenation of a deep convolutional encoder, and a fixed model-based decoder. Given an input image, and optionally 2D joint detections obtained from an independent CNN, the encoder predicts a set of hand and view parameters. The decoder has two components: A pre-computed articulated mesh deformation hand model that generates a 3D mesh from the hand parameters, and a re-projection module controlled by the view parameters that projects the generated hand into the image domain. We show that using the shape and pose prior knowledge encoded in the hand model within a deep learning framework yields state-of-the-art performance in 3D pose prediction from images on standard benchmarks, and produces geometrically valid and plausible 3D reconstructions. Additionally, we show that training with weak supervision in the form of 2D joint annotations on datasets of images in the wild, in conjunction with full supervision in the form of 3D joint annotations on limited available datasets allows for good generalization to 3D shape and pose predictions on images in the wild.
DGPose: Disentangled Semi-supervised Deep Generative Models for Human Body Analysis
Apr 17, 2018
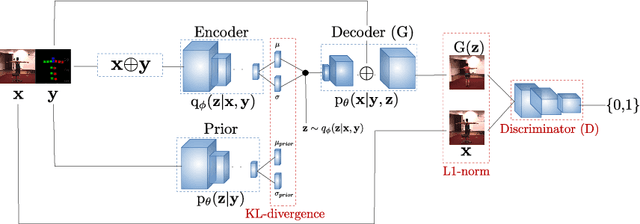
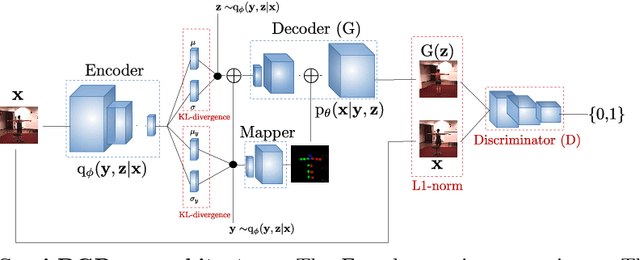
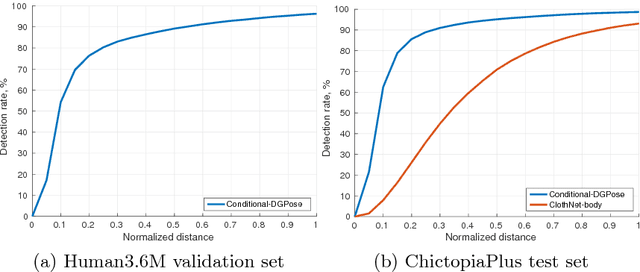
Deep generative modelling for robust human body analysis is an emerging problem with many interesting applications, since it enables analysis-by-synthesis and unsupervised learning. However, the latent space learned by such models is typically not human-interpretable, resulting in less flexible models. In this work, we adopt a structured semi-supervised variational auto-encoder approach and present a deep generative model for human body analysis where the pose and appearance are disentangled in the latent space, allowing for pose estimation. Such a disentanglement allows independent manipulation of pose and appearance and hence enables applications such as pose-transfer without being explicitly trained for such a task. In addition, the ability to train in a semi-supervised setting relaxes the need for labelled data. We demonstrate the merits of our generative model on the Human3.6M and ChictopiaPlus datasets.
Critical Percolation as a Framework to Analyze the Training of Deep Networks
Feb 06, 2018



In this paper we approach two relevant deep learning topics: i) tackling of graph structured input data and ii) a better understanding and analysis of deep networks and related learning algorithms. With this in mind we focus on the topological classification of reachability in a particular subset of planar graphs (Mazes). Doing so, we are able to model the topology of data while staying in Euclidean space, thus allowing its processing with standard CNN architectures. We suggest a suitable architecture for this problem and show that it can express a perfect solution to the classification task. The shape of the cost function around this solution is also derived and, remarkably, does not depend on the size of the maze in the large maze limit. Responsible for this behavior are rare events in the dataset which strongly regulate the shape of the cost function near this global minimum. We further identify an obstacle to learning in the form of poorly performing local minima in which the network chooses to ignore some of the inputs. We further support our claims with training experiments and numerical analysis of the cost function on networks with up to $128$ layers.