 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTCLR: Temporal Contrastive Learning for Video Representation
Paper and Code
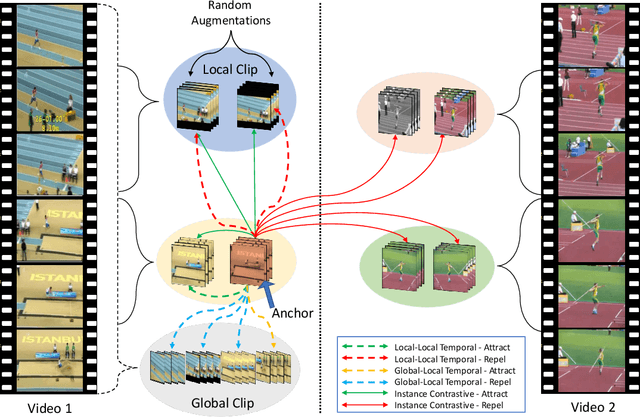
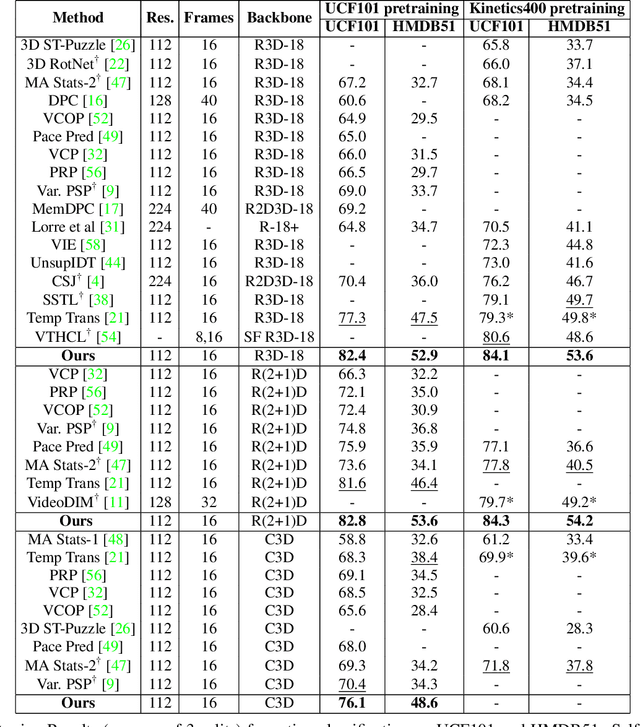
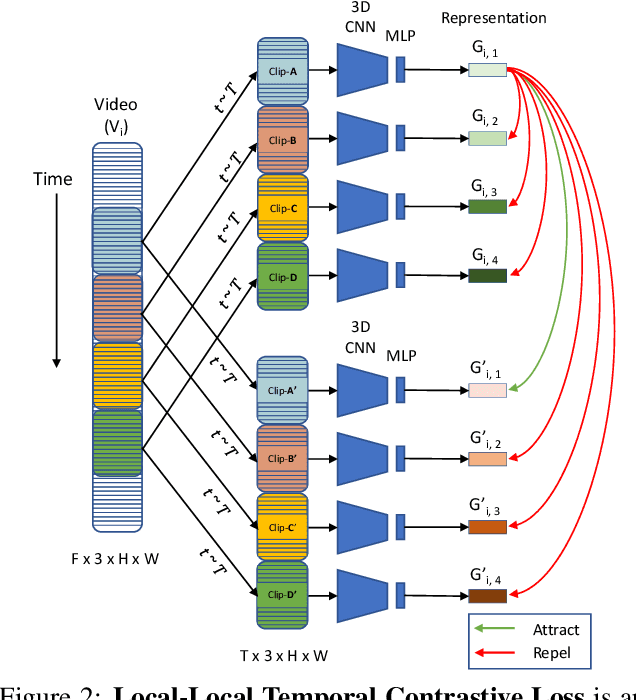

Contrastive learning has nearly closed the gap between supervised and self-supervised learning of image representations. Existing extensions of contrastive learning to the domain of video data however do not explicitly attempt to represent the internal distinctiveness across the temporal dimension of video clips. We develop a new temporal contrastive learning framework consisting of two novel losses to improve upon existing contrastive self-supervised video representation learning methods. The first loss adds the task of discriminating between non-overlapping clips from the same video, whereas the second loss aims to discriminate between timesteps of the feature map of an input clip in order to increase the temporal diversity of the features. Temporal contrastive learning achieves significant improvement over the state-of-the-art results in downstream video understanding tasks such as action recognition, limited-label action classification, and nearest-neighbor video retrieval on video datasets across multiple 3D CNN architectures. With the commonly used 3D-ResNet-18 architecture, we achieve 82.4% (+5.1% increase over the previous best) top-1 accuracy on UCF101 and 52.9% (+5.4% increase) on HMDB51 action classification, and 56.2% (+11.7% increase) Top-1 Recall on UCF101 nearest neighbor video retrieval.