 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Q Star: Principled Decoding for LLM Alignment
Paper and Code
May 30, 2024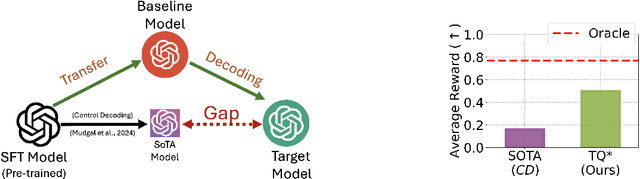



Aligning foundation models is essential for their safe and trustworthy deployment. However, traditional fine-tuning methods are computationally intensive and require updating billions of model parameters. A promising alternative, alignment via decoding, adjusts the response distribution directly without model updates to maximize a target reward $r$, thus providing a lightweight and adaptable framework for alignment. However, principled decoding methods rely on oracle access to an optimal Q-function ($Q^*$), which is often unavailable in practice. Hence, prior SoTA methods either approximate this $Q^*$ using $Q^{\pi_{\texttt{sft}}}$ (derived from the reference $\texttt{SFT}$ model) or rely on short-term rewards, resulting in sub-optimal decoding performance. In this work, we propose Transfer $Q^*$, which implicitly estimates the optimal value function for a target reward $r$ through a baseline model $\rho_{\texttt{BL}}$ aligned with a baseline reward $\rho_{\texttt{BL}}$ (which can be different from the target reward $r$). Theoretical analyses of Transfer $Q^*$ provide a rigorous characterization of its optimality, deriving an upper bound on the sub-optimality gap and identifying a hyperparameter to control the deviation from the pre-trained reference $\texttt{SFT}$ model based on user needs. Our approach significantly reduces the sub-optimality gap observed in prior SoTA methods and demonstrates superior empirical performance across key metrics such as coherence, diversity, and quality in extensive tests on several synthetic and real datasets.