 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Low-bit Communication for Tensor Parallel LLM Inference
Paper and Code
Nov 12, 2024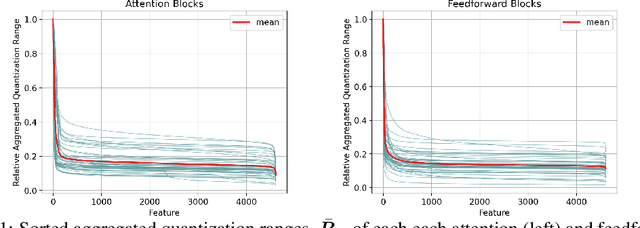
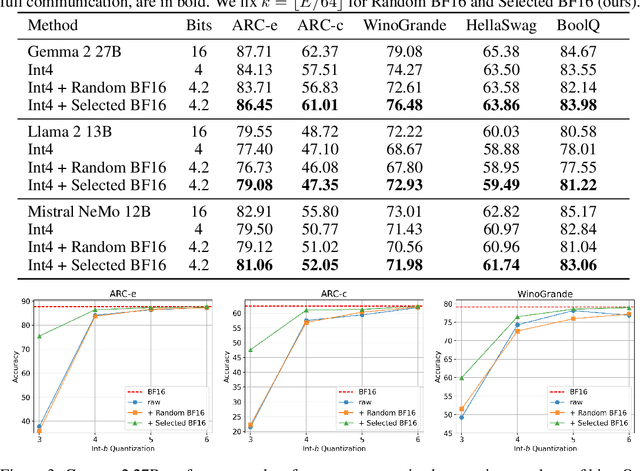

Tensor parallelism provides an effective way to increase server large language model (LLM) inference efficiency despite adding an additional communication cost. However, as server LLMs continue to scale in size, they will need to be distributed across more devices, magnifying the communication cost. One way to approach this problem is with quantization, but current methods for LLMs tend to avoid quantizing the features that tensor parallelism needs to communicate. Taking advantage of consistent outliers in communicated features, we introduce a quantization method that reduces communicated values on average from 16 bits to 4.2 bits while preserving nearly all of the original performance. For instance, our method maintains around 98.0% and 99.5% of Gemma 2 27B's and Llama 2 13B's original performance, respectively, averaged across all tasks we evaluated on.