Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplex Transformer: A Framework for Modeling Complex-Valued Sequence
Paper and Code
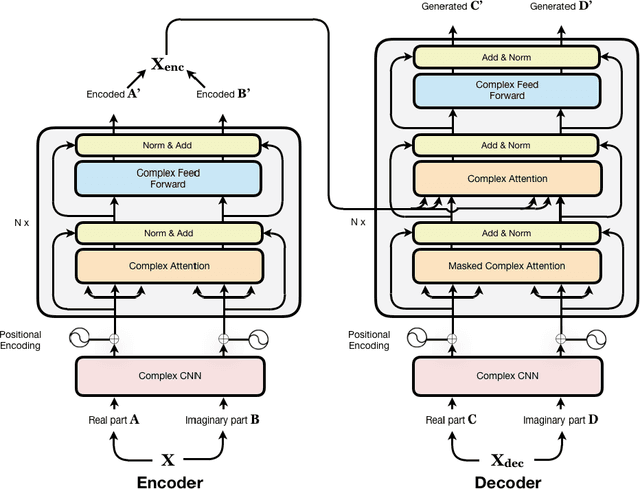
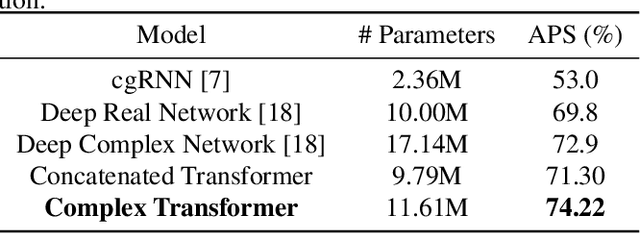
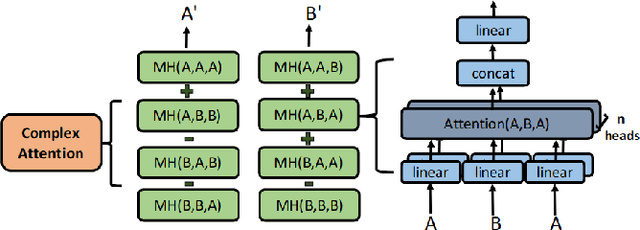

While deep learning has received a surge of interest in a variety of fields in recent years, major deep learning models barely use complex numbers. However, speech, signal and audio data are naturally complex-valued after Fourier Transform, and studies have shown a potentially richer representation of complex nets. In this paper, we propose a Complex Transformer, which incorporates the transformer model as a backbone for sequence modeling; we also develop attention and encoder-decoder network operating for complex input. The model achieves state-of-the-art performance on the MusicNet dataset and an In-phase Quadrature (IQ) signal dataset.
View paper on