 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFighting crime with Transformers: Empirical analysis of address parsing methods in payment data
Apr 09, 2024In the financial industry, identifying the location of parties involved in payments is a major challenge in the context of various regulatory requirements. For this purpose address parsing entails extracting fields such as street, postal code, or country from free text message attributes. While payment processing platforms are updating their standards with more structured formats such as SWIFT with ISO 20022, address parsing remains essential for a considerable volume of messages. With the emergence of Transformers and Generative Large Language Models (LLM), we explore the performance of state-of-the-art solutions given the constraint of processing a vast amount of daily data. This paper also aims to show the need for training robust models capable of dealing with real-world noisy transactional data. Our results suggest that a well fine-tuned Transformer model using early-stopping significantly outperforms other approaches. Nevertheless, generative LLMs demonstrate strong zero-shot performance and warrant further investigations.
Embedding Individual Table Columns for Resilient SQL Chatbots
Nov 01, 2018
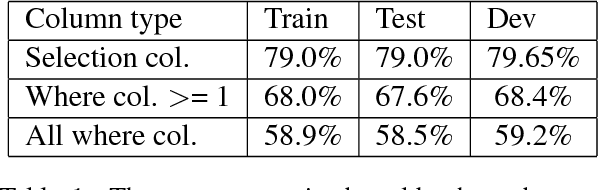
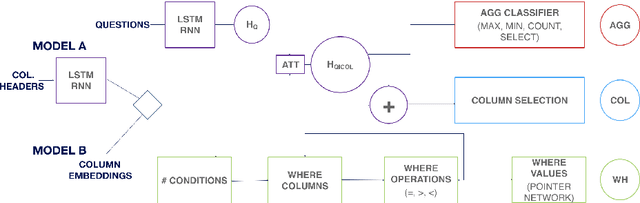

Most of the world's data is stored in relational databases. Accessing these requires specialized knowledge of the Structured Query Language (SQL), putting them out of the reach of many people. A recent research thread in Natural Language Processing (NLP) aims to alleviate this problem by automatically translating natural language questions into SQL queries. While the proposed solutions are a great start, they lack robustness and do not easily generalize: the methods require high quality descriptions of the database table columns, and the most widely used training dataset, WikiSQL, is heavily biased towards using those descriptions as part of the questions. In this work, we propose solutions to both problems: we entirely eliminate the need for column descriptions, by relying solely on their contents, and we augment the WikiSQL dataset by paraphrasing column names to reduce bias. We show that the accuracy of existing methods drops when trained on our augmented, column-agnostic dataset, and that our own method reaches state of the art accuracy, while relying on column contents only.