 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoal-Oriented Chatbot Dialog Management Bootstrapping with Transfer Learning
Jul 24, 2018
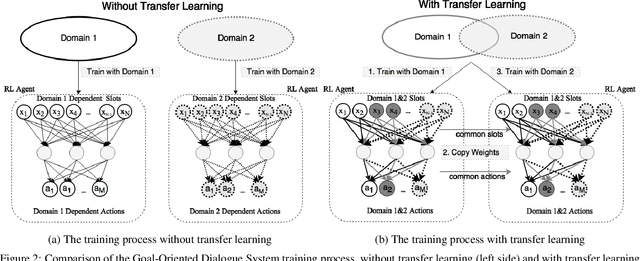
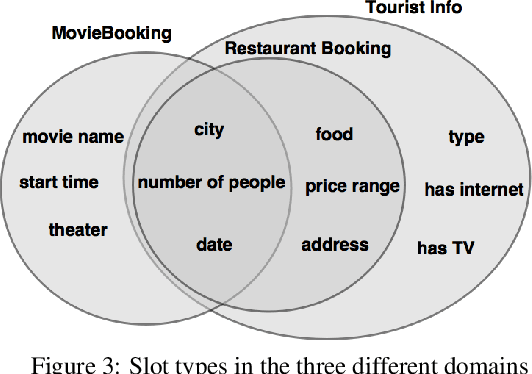
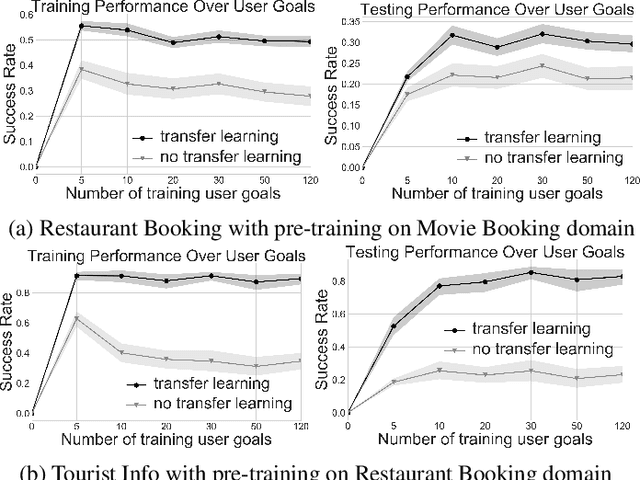
Goal-Oriented (GO) Dialogue Systems, colloquially known as goal oriented chatbots, help users achieve a predefined goal (e.g. book a movie ticket) within a closed domain. A first step is to understand the user's goal by using natural language understanding techniques. Once the goal is known, the bot must manage a dialogue to achieve that goal, which is conducted with respect to a learnt policy. The success of the dialogue system depends on the quality of the policy, which is in turn reliant on the availability of high-quality training data for the policy learning method, for instance Deep Reinforcement Learning. Due to the domain specificity, the amount of available data is typically too low to allow the training of good dialogue policies. In this paper we introduce a transfer learning method to mitigate the effects of the low in-domain data availability. Our transfer learning based approach improves the bot's success rate by 20% in relative terms for distant domains and we more than double it for close domains, compared to the model without transfer learning. Moreover, the transfer learning chatbots learn the policy up to 5 to 10 times faster. Finally, as the transfer learning approach is complementary to additional processing such as warm-starting, we show that their joint application gives the best outcomes.
Submodularity-Inspired Data Selection for Goal-Oriented Chatbot Training Based on Sentence Embeddings
Jul 08, 2018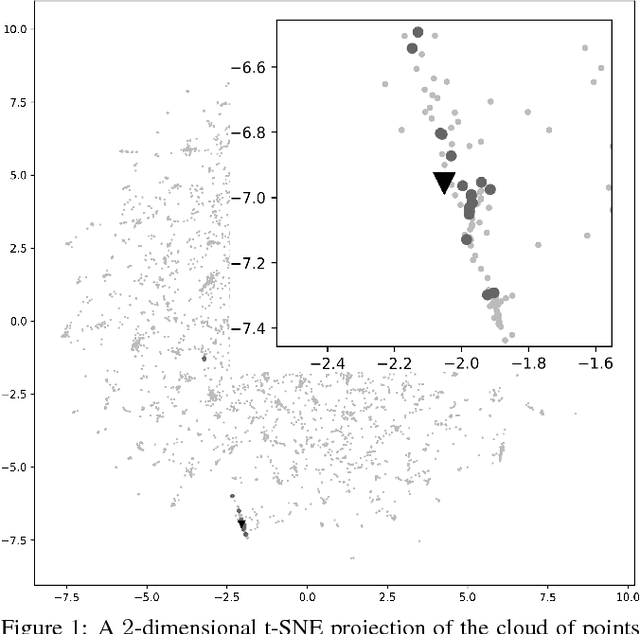
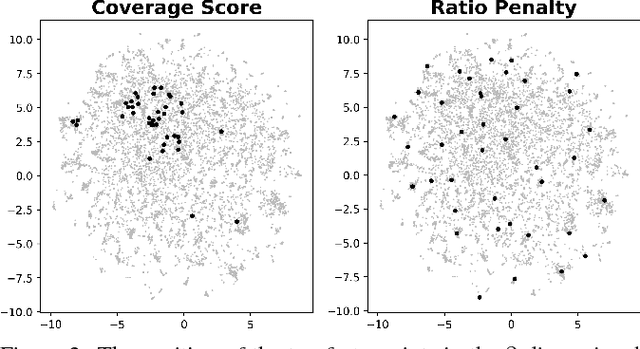


Spoken language understanding (SLU) systems, such as goal-oriented chatbots or personal assistants, rely on an initial natural language understanding (NLU) module to determine the intent and to extract the relevant information from the user queries they take as input. SLU systems usually help users to solve problems in relatively narrow domains and require a large amount of in-domain training data. This leads to significant data availability issues that inhibit the development of successful systems. To alleviate this problem, we propose a technique of data selection in the low-data regime that enables us to train with fewer labeled sentences, thus smaller labelling costs. We propose a submodularity-inspired data ranking function, the ratio-penalty marginal gain, for selecting data points to label based only on the information extracted from the textual embedding space. We show that the distances in the embedding space are a viable source of information that can be used for data selection. Our method outperforms two known active learning techniques and enables cost-efficient training of the NLU unit. Moreover, our proposed selection technique does not need the model to be retrained in between the selection steps, making it time efficient as well.
Building Advanced Dialogue Managers for Goal-Oriented Dialogue Systems
Jun 03, 2018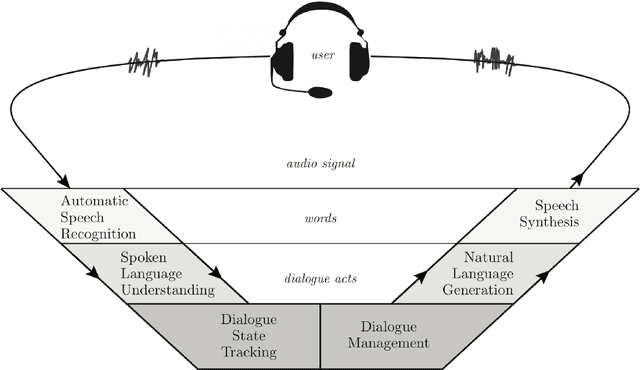
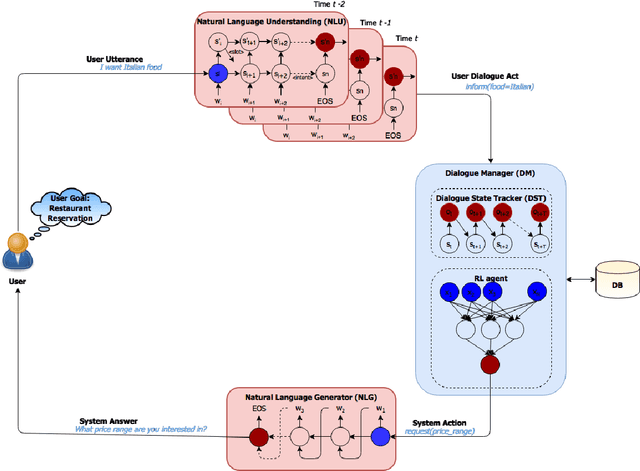
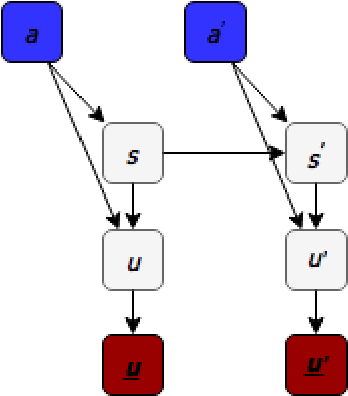
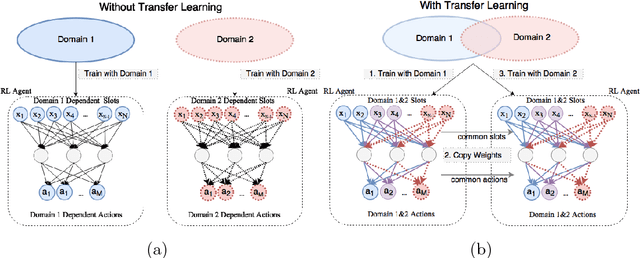
Goal-Oriented (GO) Dialogue Systems, colloquially known as goal oriented chatbots, help users achieve a predefined goal (e.g. book a movie ticket) within a closed domain. A first step is to understand the user's goal by using natural language understanding techniques. Once the goal is known, the bot must manage a dialogue to achieve that goal, which is conducted with respect to a learnt policy. The success of the dialogue system depends on the quality of the policy, which is in turn reliant on the availability of high-quality training data for the policy learning method, for instance Deep Reinforcement Learning. Due to the domain specificity, the amount of available data is typically too low to allow the training of good dialogue policies. In this master thesis we introduce a transfer learning method to mitigate the effects of the low in-domain data availability. Our transfer learning based approach improves the bot's success rate by $20\%$ in relative terms for distant domains and we more than double it for close domains, compared to the model without transfer learning. Moreover, the transfer learning chatbots learn the policy up to 5 to 10 times faster. Finally, as the transfer learning approach is complementary to additional processing such as warm-starting, we show that their joint application gives the best outcomes.