 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIVA-DAF: A Deep Learning Framework for Historical Document Image Analysis
Jan 21, 2022

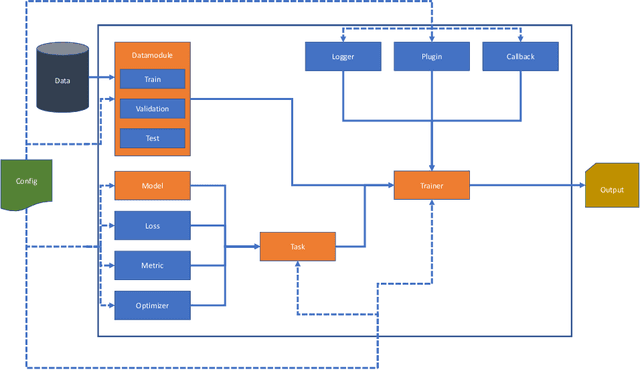
In this paper, we introduce a new deep learning framework called DIVA-DAF. We have developed this framework to support our research on historical document image analysis tasks and to develop techniques to reduce the need for manually-labeled ground truth. We want to apply self-supervised learning techniques and use different kinds of training data. Our new framework aids us in performing rapid prototyping and reproducible experiments. We present a first semantic segmentation experiment on DIVA-HisDB using our framework, achieving state-of-the-art results. The DIVA-DAF framework is open-source, and we encourage other research groups to use it for their experiments.
Graph-Based Offline Signature Verification
Jun 25, 2019

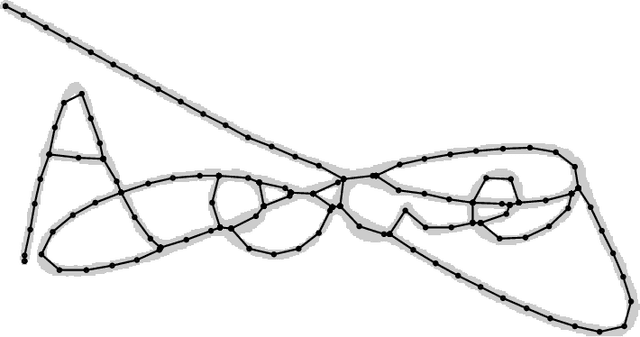
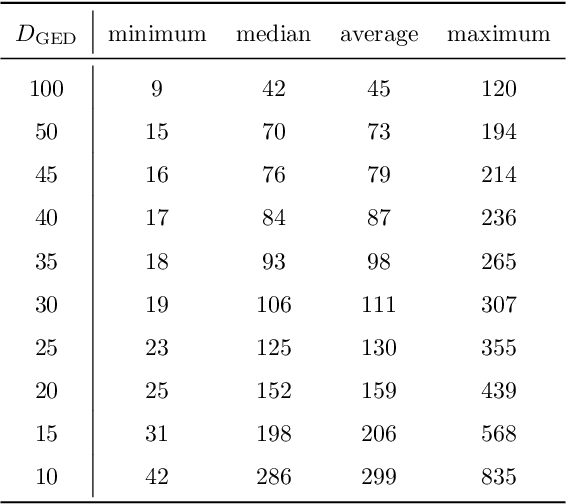
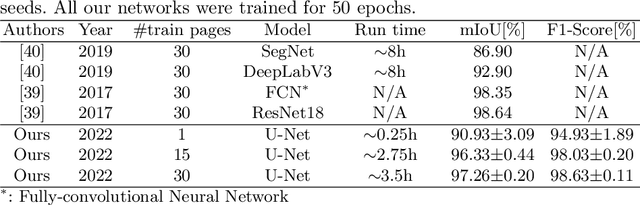
Graphs provide a powerful representation formalism that offers great promise to benefit tasks like handwritten signature verification. While most state-of-the-art approaches to signature verification rely on fixed-size representations, graphs are flexible in size and allow modeling local features as well as the global structure of the handwriting. In this article, we present two recent graph-based approaches to offline signature verification: keypoint graphs with approximated graph edit distance and inkball models. We provide a comprehensive description of the methods, propose improvements both in terms of computational time and accuracy, and report experimental results for four benchmark datasets. The proposed methods achieve top results for several benchmarks, highlighting the potential of graph-based signature verification.
Offline Signature Verification by Combining Graph Edit Distance and Triplet Networks
Oct 17, 2018
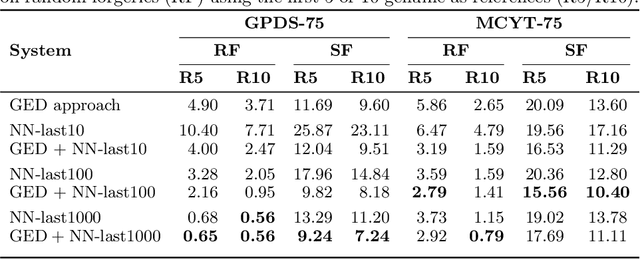
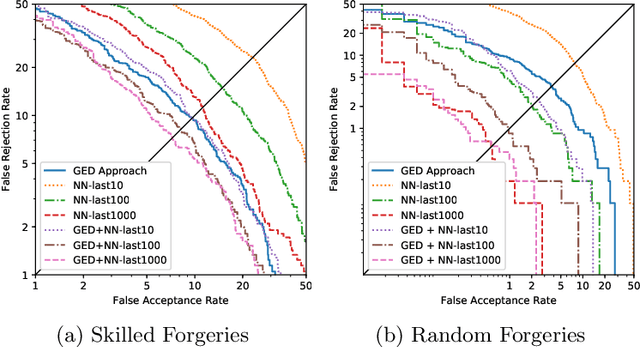
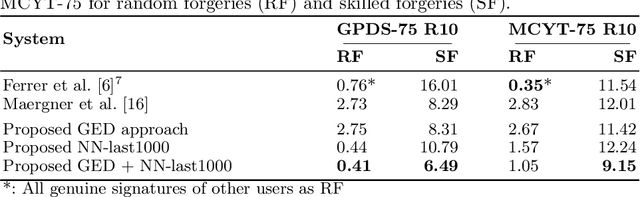
Biometric authentication by means of handwritten signatures is a challenging pattern recognition task, which aims to infer a writer model from only a handful of genuine signatures. In order to make it more difficult for a forger to attack the verification system, a promising strategy is to combine different writer models. In this work, we propose to complement a recent structural approach to offline signature verification based on graph edit distance with a statistical approach based on metric learning with deep neural networks. On the MCYT and GPDS benchmark datasets, we demonstrate that combining the structural and statistical models leads to significant improvements in performance, profiting from their complementary properties.