 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Multiscenario Multienvironment BioSecure Multimodal Database (BMDB)
Nov 17, 2021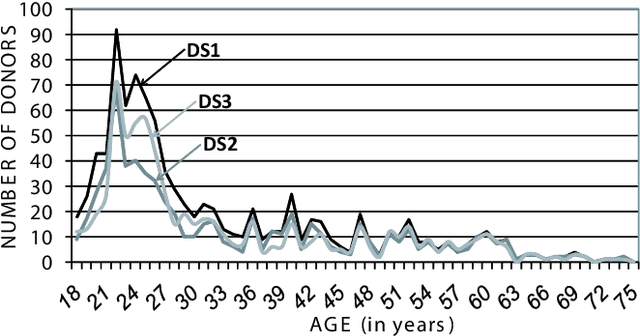

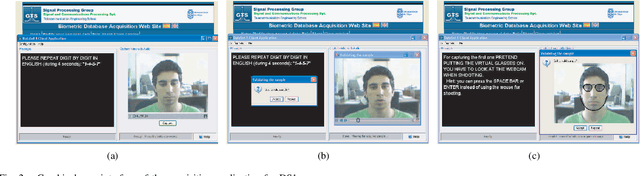

A new multimodal biometric database designed and acquired within the framework of the European BioSecure Network of Excellence is presented. It is comprised of more than 600 individuals acquired simultaneously in three scenarios: 1) over the Internet, 2) in an office environment with desktop PC, and 3) in indoor/outdoor environments with mobile portable hardware. The three scenarios include a common part of audio/video data. Also, signature and fingerprint data have been acquired both with desktop PC and mobile portable hardware. Additionally, hand and iris data were acquired in the second scenario using desktop PC. Acquisition has been conducted by 11 European institutions. Additional features of the BioSecure Multimodal Database (BMDB) are: two acquisition sessions, several sensors in certain modalities, balanced gender and age distributions, multimodal realistic scenarios with simple and quick tasks per modality, cross-European diversity, availability of demographic data, and compatibility with other multimodal databases. The novel acquisition conditions of the BMDB allow us to perform new challenging research and evaluation of either monomodal or multimodal biometric systems, as in the recent BioSecure Multimodal Evaluation campaign. A description of this campaign including baseline results of individual modalities from the new database is also given. The database is expected to be available for research purposes through the BioSecure Association during 2008
Automatic Creation of Text Corpora for Low-Resource Languages from the Internet: The Case of Swiss German
Nov 30, 2019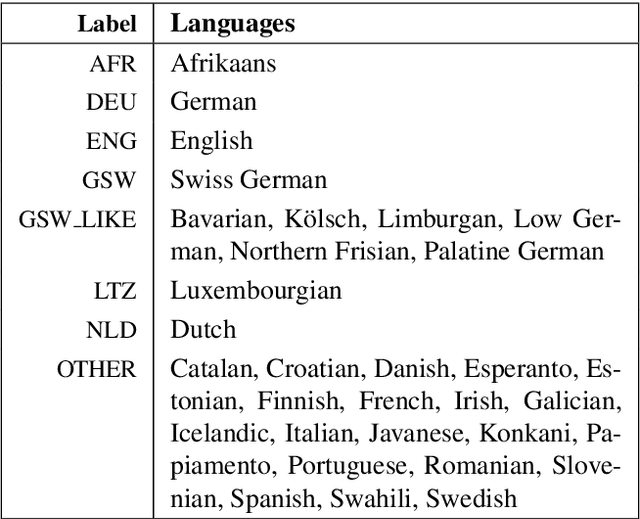
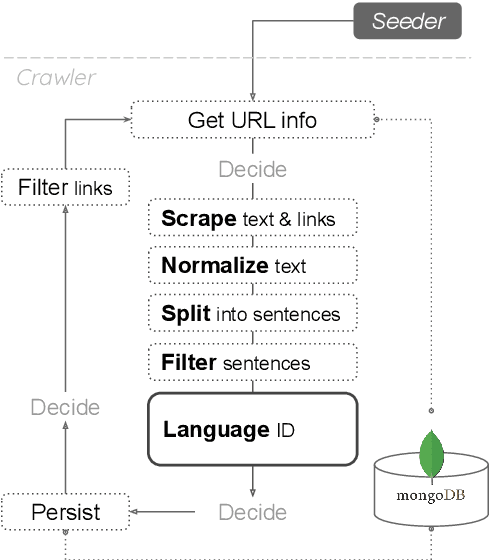
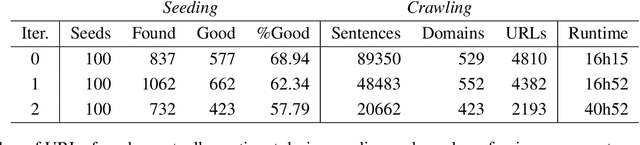
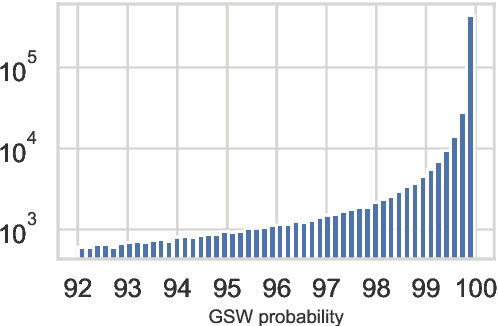
This paper presents SwissCrawl, the largest Swiss German text corpus to date. Composed of more than half a million sentences, it was generated using a customized web scraping tool that could be applied to other low-resource languages as well. The approach demonstrates how freely available web pages can be used to construct comprehensive text corpora, which are of fundamental importance for natural language processing. In an experimental evaluation, we show that using the new corpus leads to significant improvements for the task of language modeling. To capture new content, our approach will run continuously to keep increasing the corpus over time.
DLL: A Blazing Fast Deep Neural Network Library
Apr 11, 2018
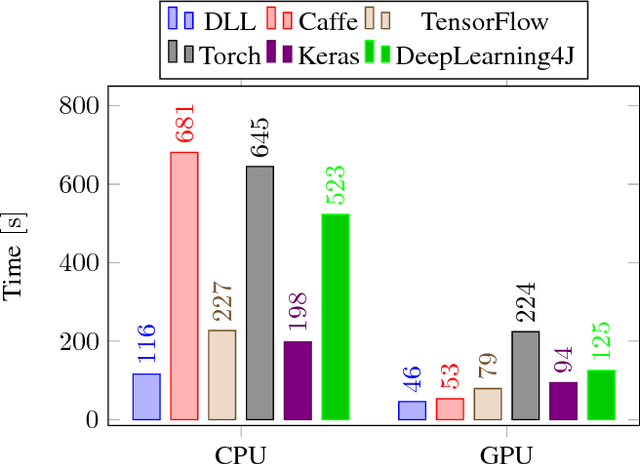
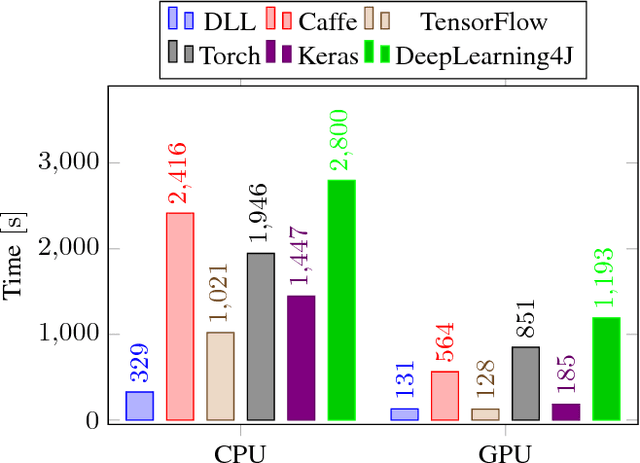
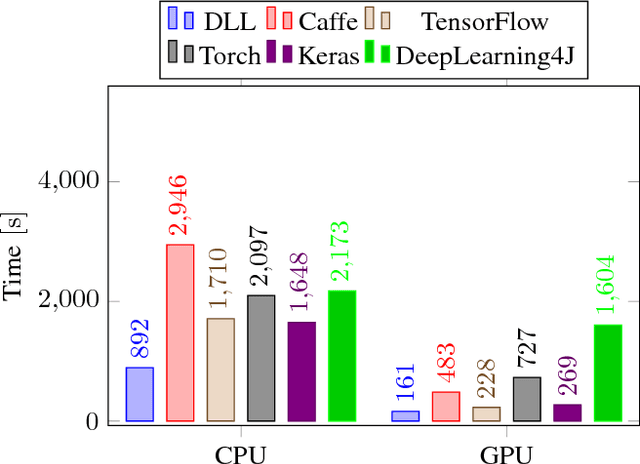
Deep Learning Library (DLL) is a new library for machine learning with deep neural networks that focuses on speed. It supports feed-forward neural networks such as fully-connected Artificial Neural Networks (ANNs) and Convolutional Neural Networks (CNNs). It also has very comprehensive support for Restricted Boltzmann Machines (RBMs) and Convolutional RBMs. Our main motivation for this work was to propose and evaluate novel software engineering strategies with potential to accelerate runtime for training and inference. Such strategies are mostly independent of the underlying deep learning algorithms. On three different datasets and for four different neural network models, we compared DLL to five popular deep learning frameworks. Experimentally, it is shown that the proposed framework is systematically and significantly faster on CPU and GPU. In terms of classification performance, similar accuracies as the other frameworks are reported.