 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Multi-Agent Model-Based Reinforcement Learning
Paper and Code
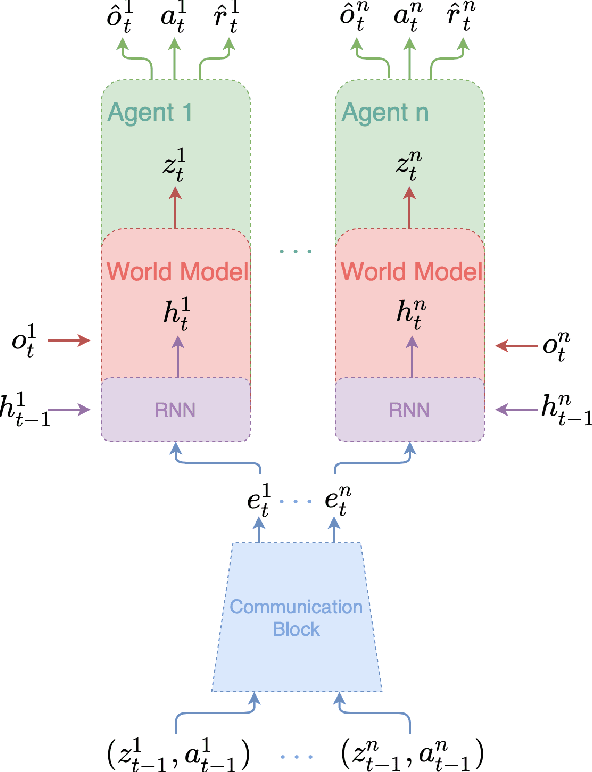
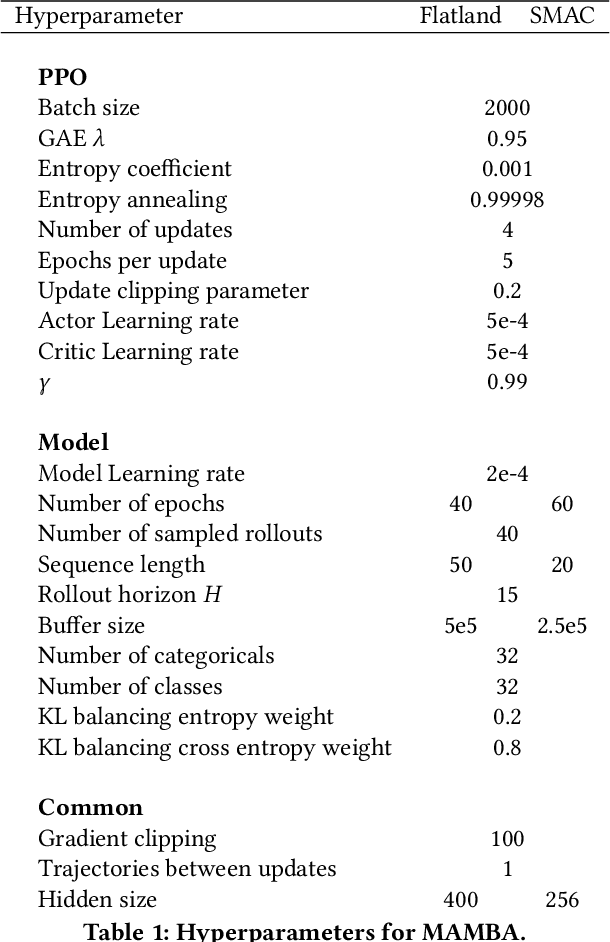
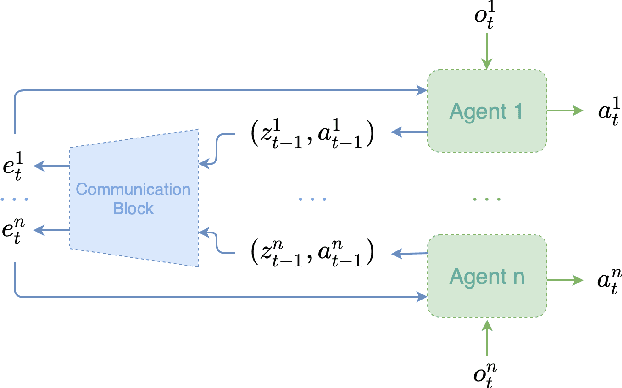
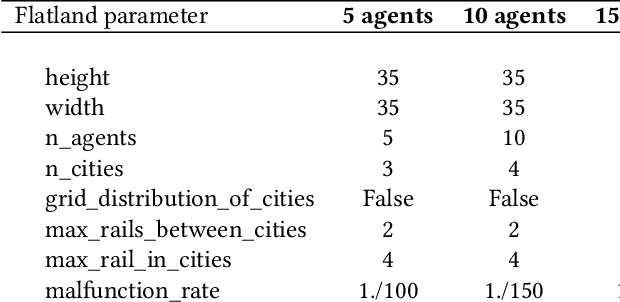
Recent Multi-Agent Reinforcement Learning (MARL) literature has been largely focused on Centralized Training with Decentralized Execution (CTDE) paradigm. CTDE has been a dominant approach for both cooperative and mixed environments due to its capability to efficiently train decentralized policies. While in mixed environments full autonomy of the agents can be a desirable outcome, cooperative environments allow agents to share information to facilitate coordination. Approaches that leverage this technique are usually referred as communication methods, as full autonomy of agents is compromised for better performance. Although communication approaches have shown impressive results, they do not fully leverage this additional information during training phase. In this paper, we propose a new method called MAMBA which utilizes Model-Based Reinforcement Learning (MBRL) to further leverage centralized training in cooperative environments. We argue that communication between agents is enough to sustain a world model for each agent during execution phase while imaginary rollouts can be used for training, removing the necessity to interact with the environment. These properties yield sample efficient algorithm that can scale gracefully with the number of agents. We empirically confirm that MAMBA achieves good performance while reducing the number of interactions with the environment up to an orders of magnitude compared to Model-Free state-of-the-art approaches in challenging domains of SMAC and Flatland.