 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASR Benchmarking: Need for a More Representative Conversational Dataset
Sep 18, 2024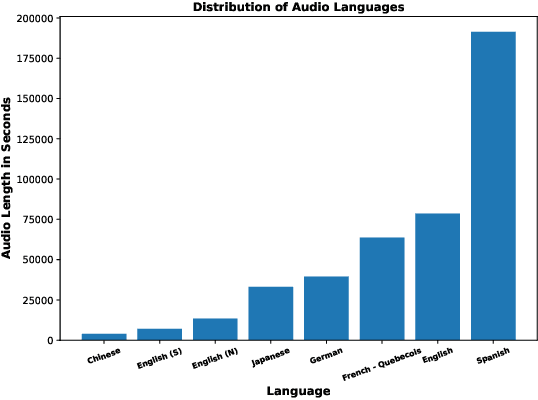

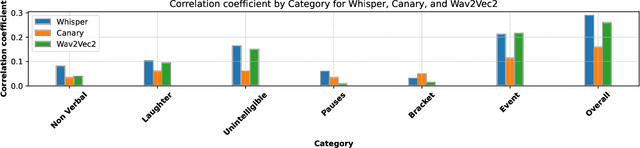
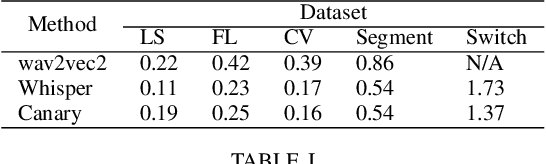
Automatic Speech Recognition (ASR) systems have achieved remarkable performance on widely used benchmarks such as LibriSpeech and Fleurs. However, these benchmarks do not adequately reflect the complexities of real-world conversational environments, where speech is often unstructured and contains disfluencies such as pauses, interruptions, and diverse accents. In this study, we introduce a multilingual conversational dataset, derived from TalkBank, consisting of unstructured phone conversation between adults. Our results show a significant performance drop across various state-of-the-art ASR models when tested in conversational settings. Furthermore, we observe a correlation between Word Error Rate and the presence of speech disfluencies, highlighting the critical need for more realistic, conversational ASR benchmarks.