 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning under Invariable Bayesian Safety
Paper and Code
Jun 08, 2020
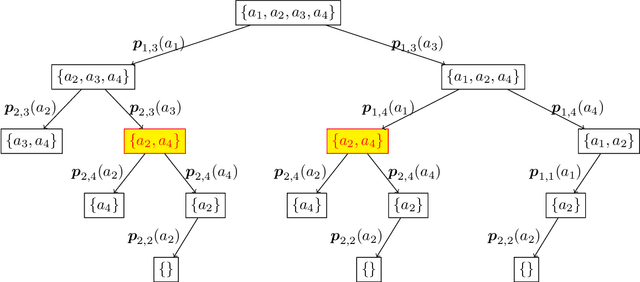
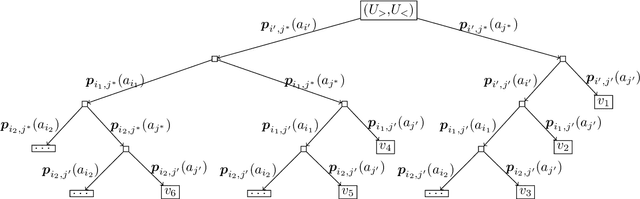
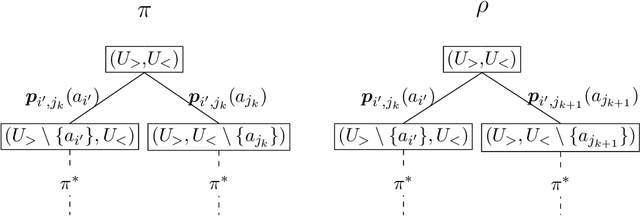
A recent body of work addresses safety constraints in explore-and-exploit systems. Such constraints arise where, for example, exploration is carried out by individuals whose welfare should be balanced with overall welfare. In this paper, we adopt a model inspired by recent work on a bandit-like setting for recommendations. We contribute to this line of literature by introducing a safety constraint that should be respected in every round and determines that the expected value in each round is above a given threshold. Due to our modeling, the safe explore-and-exploit policy deserves careful planning, or otherwise, it will lead to sub-optimal welfare. We devise an asymptotically optimal algorithm for the setting and analyze its instance-dependent convergence rate.