 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferable Representation Learning in Vision-and-Language Navigation
Aug 12, 2019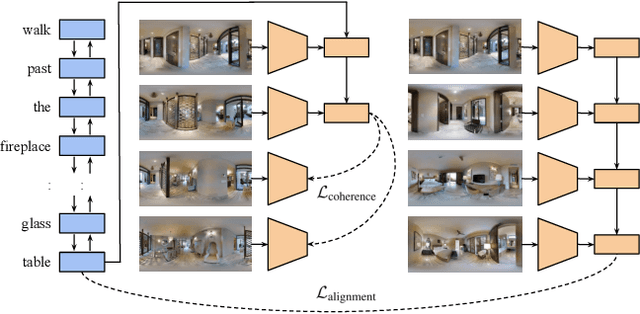


Vision-and-Language Navigation (VLN) tasks such as Room-to-Room (R2R) require machine agents to interpret natural language instructions and learn to act in visually realistic environments to achieve navigation goals. The overall task requires competence in several perception problems: successful agents combine spatio-temporal, vision and language understanding to produce appropriate action sequences. Our approach adapts pre-trained vision and language representations to relevant in-domain tasks making them more effective for VLN. Specifically, the representations are adapted to solve both a cross-modal sequence alignment and sequence coherence task. In the sequence alignment task, the model determines whether an instruction corresponds to a sequence of visual frames. In the sequence coherence task, the model determines whether the perceptual sequences are predictive sequentially in the instruction-conditioned latent space. By transferring the domain-adapted representations, we improve competitive agents in R2R as measured by the success rate weighted by path length (SPL) metric.
Effective and General Evaluation for Instruction Conditioned Navigation using Dynamic Time Warping
Jul 11, 2019



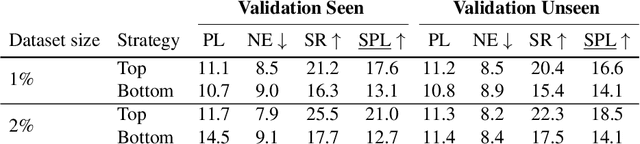
In instruction conditioned navigation, agents interpret natural language and their surroundings to navigate through an environment. Datasets for studying this task typically contain pairs of these instructions and reference trajectories. Yet, most evaluation metrics used thus far fail to properly account for the latter, relying instead on insufficient similarity comparisons. We address fundamental flaws in previously used metrics and show how Dynamic Time Warping (DTW), a long known method of measuring similarity between two time series, can be used for evaluation of navigation agents. For such, we define the normalized Dynamic Time Warping (nDTW) metric, that softly penalizes deviations from the reference path, is naturally sensitive to the order of the nodes composing each path, is suited for both continuous and graph-based evaluations, and can be efficiently calculated. Further, we define SDTW, which constrains nDTW to only successful paths. We collect human similarity judgments for simulated paths and find nDTW correlates better with human rankings than all other metrics. We also demonstrate that using nDTW as a reward signal for Reinforcement Learning navigation agents improves their performance on both the Room-to-Room (R2R) and Room-for-Room (R4R) datasets. The R4R results in particular highlight the superiority of SDTW over previous success-constrained metrics.
Stay on the Path: Instruction Fidelity in Vision-and-Language Navigation
Jun 04, 2019



Advances in learning and representations have reinvigorated work that connects language to other modalities. A particularly exciting direction is Vision-and-Language Navigation(VLN), in which agents interpret natural language instructions and visual scenes to move through environments and reach goals. Despite recent progress, current research leaves unclear how much of a role language understanding plays in this task, especially because dominant evaluation metrics have focused on goal completion rather than the sequence of actions corresponding to the instructions. Here, we highlight shortcomings of current metrics for the Room-to-Room dataset (Anderson et al.,2018b) and propose a new metric, Coverage weighted by Length Score (CLS). We also show that the existing paths in the dataset are not ideal for evaluating instruction following because they are direct-to-goal shortest paths. We join existing short paths to form more challenging extended paths to create a new data set, Room-for-Room (R4R). Using R4R and CLS, we show that agents that receive rewards for instruction fidelity outperform agents that focus on goal completion.