 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAria: An Open Multimodal Native Mixture-of-Experts Model
Paper and Code

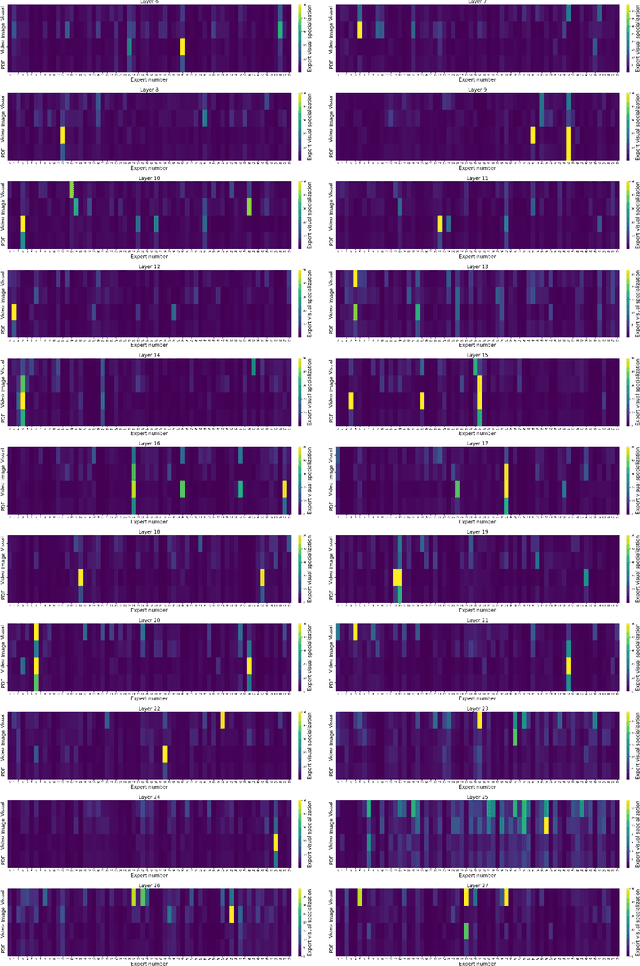


Information comes in diverse modalities. Multimodal native AI models are essential to integrate real-world information and deliver comprehensive understanding. While proprietary multimodal native models exist, their lack of openness imposes obstacles for adoptions, let alone adaptations. To fill this gap, we introduce Aria, an open multimodal native model with best-in-class performance across a wide range of multimodal, language, and coding tasks. Aria is a mixture-of-expert model with 3.9B and 3.5B activated parameters per visual token and text token, respectively. It outperforms Pixtral-12B and Llama3.2-11B, and is competitive against the best proprietary models on various multimodal tasks. We pre-train Aria from scratch following a 4-stage pipeline, which progressively equips the model with strong capabilities in language understanding, multimodal understanding, long context window, and instruction following. We open-source the model weights along with a codebase that facilitates easy adoptions and adaptations of Aria in real-world applications.