 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlug-and-Play VQA: Zero-shot VQA by Conjoining Large Pretrained Models with Zero Training
Paper and Code
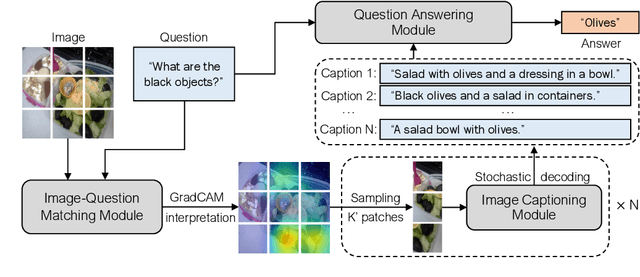
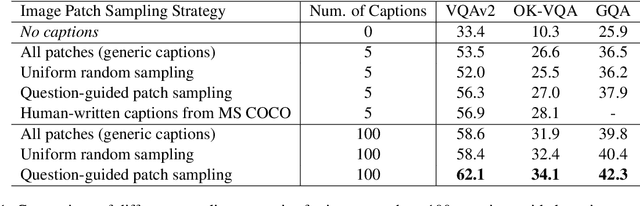

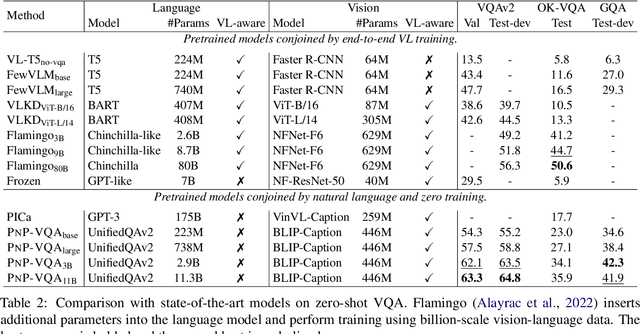
Visual question answering (VQA) is a hallmark of vision and language reasoning and a challenging task under the zero-shot setting. We propose Plug-and-Play VQA (PNP-VQA), a modular framework for zero-shot VQA. In contrast to most existing works, which require substantial adaptation of pretrained language models (PLMs) for the vision modality, PNP-VQA requires no additional training of the PLMs. Instead, we propose to use natural language and network interpretation as an intermediate representation that glues pretrained models together. We first generate question-guided informative image captions, and pass the captions to a PLM as context for question answering. Surpassing end-to-end trained baselines, PNP-VQA achieves state-of-the-art results on zero-shot VQAv2 and GQA. With 11B parameters, it outperforms the 80B-parameter Flamingo model by 8.5% on VQAv2. With 738M PLM parameters, PNP-VQA achieves an improvement of 9.1% on GQA over FewVLM with 740M PLM parameters. Code is released at https://github.com/salesforce/LAVIS/tree/main/projects/pnp-vqa