 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving SAM Requires Rethinking its Optimization Formulation
Jul 17, 2024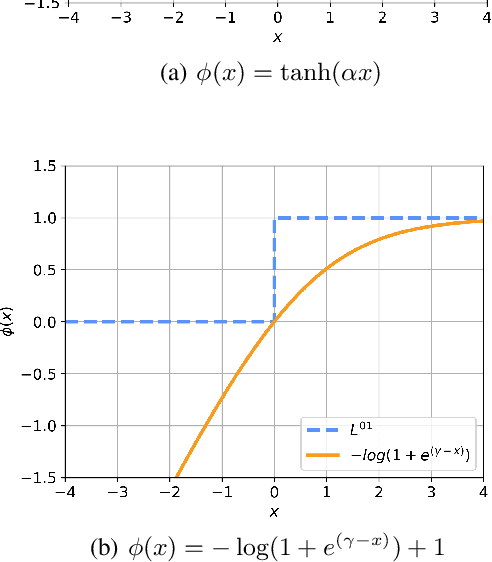

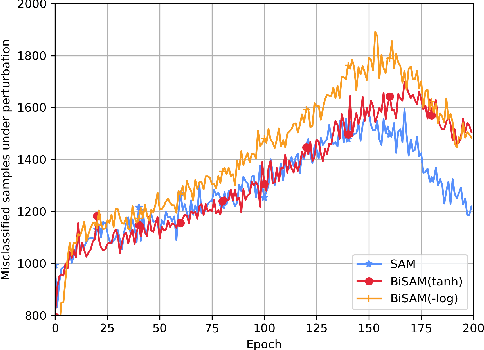
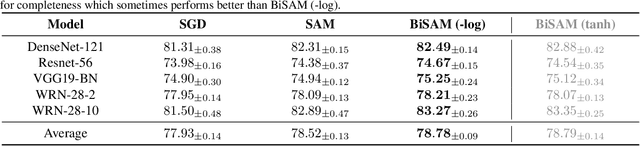
This paper rethinks Sharpness-Aware Minimization (SAM), which is originally formulated as a zero-sum game where the weights of a network and a bounded perturbation try to minimize/maximize, respectively, the same differentiable loss. To fundamentally improve this design, we argue that SAM should instead be reformulated using the 0-1 loss. As a continuous relaxation, we follow the simple conventional approach where the minimizing (maximizing) player uses an upper bound (lower bound) surrogate to the 0-1 loss. This leads to a novel formulation of SAM as a bilevel optimization problem, dubbed as BiSAM. BiSAM with newly designed lower-bound surrogate loss indeed constructs stronger perturbation. Through numerical evidence, we show that BiSAM consistently results in improved performance when compared to the original SAM and variants, while enjoying similar computational complexity. Our code is available at https://github.com/LIONS-EPFL/BiSAM.
Adversarial Training Should Be Cast as a Non-Zero-Sum Game
Jun 19, 2023


One prominent approach toward resolving the adversarial vulnerability of deep neural networks is the two-player zero-sum paradigm of adversarial training, in which predictors are trained against adversarially-chosen perturbations of data. Despite the promise of this approach, algorithms based on this paradigm have not engendered sufficient levels of robustness, and suffer from pathological behavior like robust overfitting. To understand this shortcoming, we first show that the commonly used surrogate-based relaxation used in adversarial training algorithms voids all guarantees on the robustness of trained classifiers. The identification of this pitfall informs a novel non-zero-sum bilevel formulation of adversarial training, wherein each player optimizes a different objective function. Our formulation naturally yields a simple algorithmic framework that matches and in some cases outperforms state-of-the-art attacks, attains comparable levels of robustness to standard adversarial training algorithms, and does not suffer from robust overfitting.
OTW: Optimal Transport Warping for Time Series
Jun 01, 2023
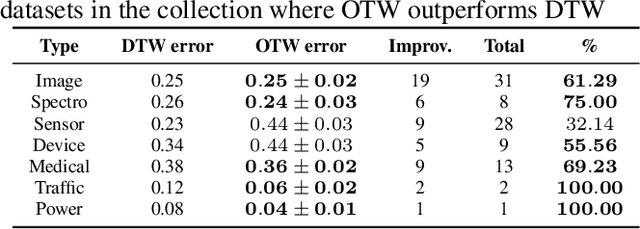
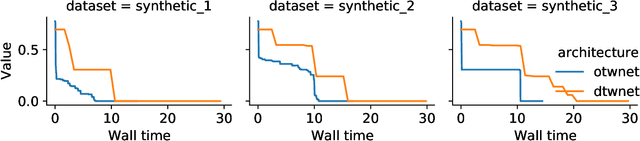
Dynamic Time Warping (DTW) has become the pragmatic choice for measuring distance between time series. However, it suffers from unavoidable quadratic time complexity when the optimal alignment matrix needs to be computed exactly. This hinders its use in deep learning architectures, where layers involving DTW computations cause severe bottlenecks. To alleviate these issues, we introduce a new metric for time series data based on the Optimal Transport (OT) framework, called Optimal Transport Warping (OTW). OTW enjoys linear time/space complexity, is differentiable and can be parallelized. OTW enjoys a moderate sensitivity to time and shape distortions, making it ideal for time series. We show the efficacy and efficiency of OTW on 1-Nearest Neighbor Classification and Hierarchical Clustering, as well as in the case of using OTW instead of DTW in Deep Learning architectures.
Controlling the Complexity and Lipschitz Constant improves polynomial nets
Feb 10, 2022
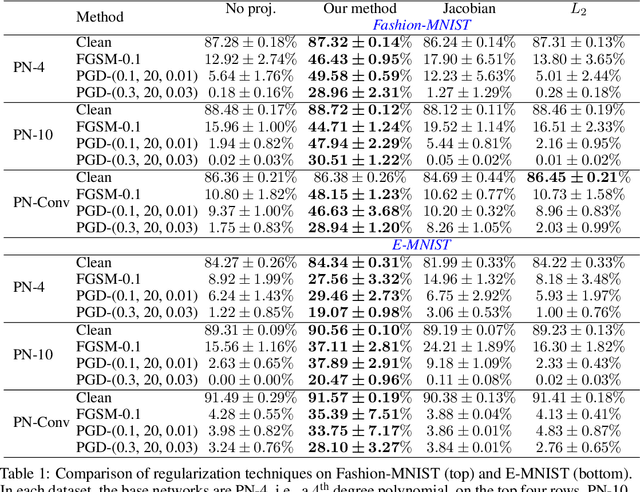
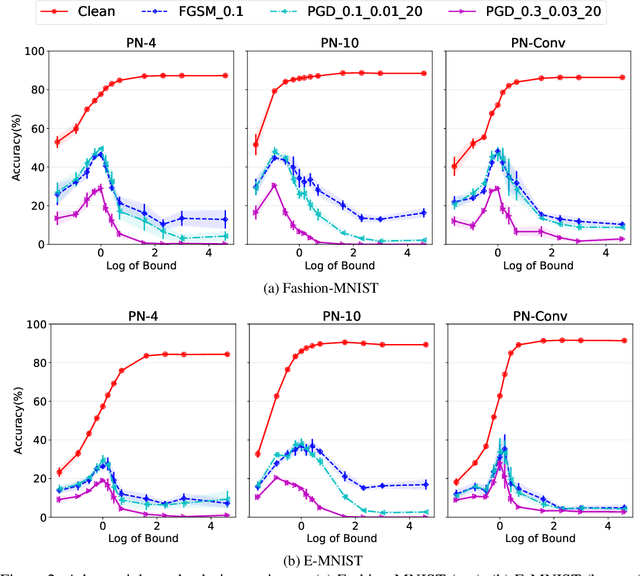
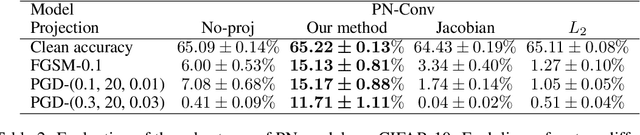
While the class of Polynomial Nets demonstrates comparable performance to neural networks (NN), it currently has neither theoretical generalization characterization nor robustness guarantees. To this end, we derive new complexity bounds for the set of Coupled CP-Decomposition (CCP) and Nested Coupled CP-decomposition (NCP) models of Polynomial Nets in terms of the $\ell_\infty$-operator-norm and the $\ell_2$-operator norm. In addition, we derive bounds on the Lipschitz constant for both models to establish a theoretical certificate for their robustness. The theoretical results enable us to propose a principled regularization scheme that we also evaluate experimentally in six datasets and show that it improves the accuracy as well as the robustness of the models to adversarial perturbations. We showcase how this regularization can be combined with adversarial training, resulting in further improvements.
Efficient Proximal Mapping of the 1-path-norm of Shallow Networks
Jul 15, 2020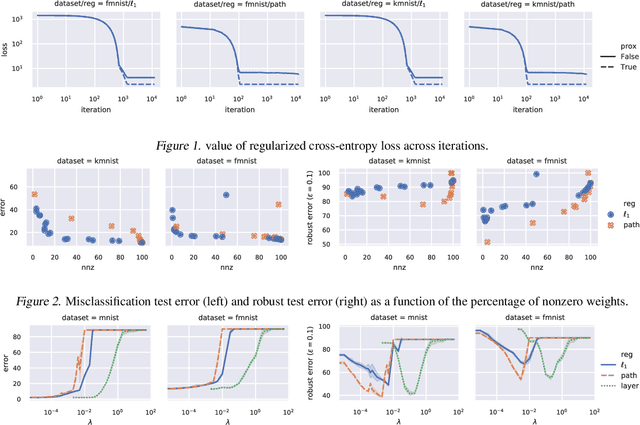
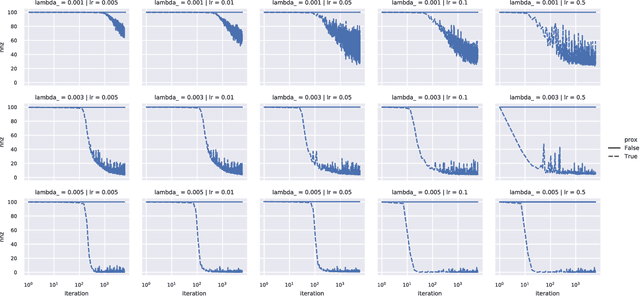
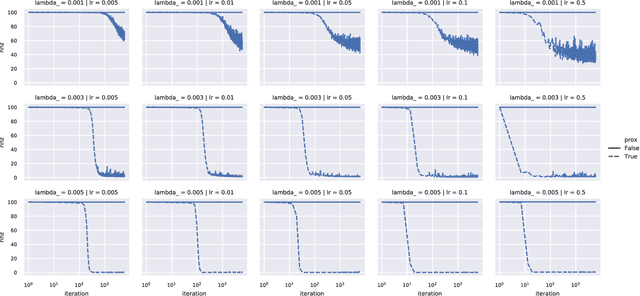
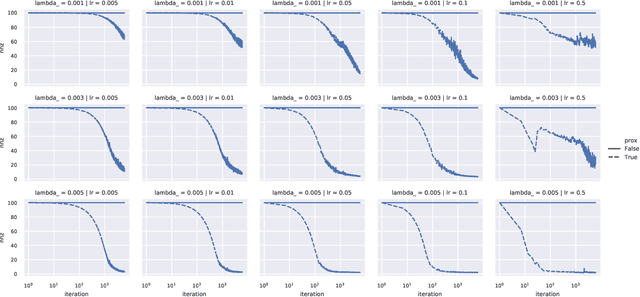
We demonstrate two new important properties of the 1-path-norm of shallow neural networks. First, despite its non-smoothness and non-convexity it allows a closed form proximal operator which can be efficiently computed, allowing the use of stochastic proximal-gradient-type methods for regularized empirical risk minimization. Second, when the activation functions is differentiable, it provides an upper bound on the Lipschitz constant of the network. Such bound is tighter than the trivial layer-wise product of Lipschitz constants, motivating its use for training networks robust to adversarial perturbations. In practical experiments we illustrate the advantages of using the proximal mapping and we compare the robustness-accuracy trade-off induced by the 1-path-norm, L1-norm and layer-wise constraints on the Lipschitz constant (Parseval networks).
Lipschitz constant estimation of Neural Networks via sparse polynomial optimization
Apr 18, 2020
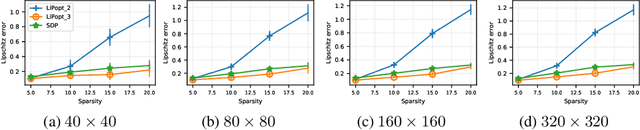
We introduce LiPopt, a polynomial optimization framework for computing increasingly tighter upper bounds on the Lipschitz constant of neural networks. The underlying optimization problems boil down to either linear (LP) or semidefinite (SDP) programming. We show how to use the sparse connectivity of a network, to significantly reduce the complexity of computation. This is specially useful for convolutional as well as pruned neural networks. We conduct experiments on networks with random weights as well as networks trained on MNIST, showing that in the particular case of the $\ell_\infty$-Lipschitz constant, our approach yields superior estimates, compared to baselines available in the literature.