 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving SAM Requires Rethinking its Optimization Formulation
Paper and Code
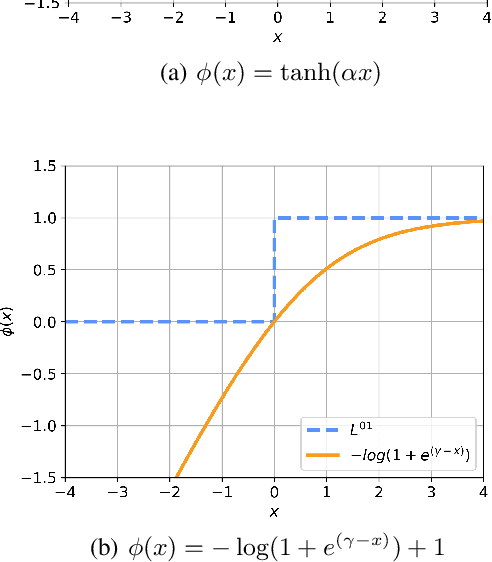

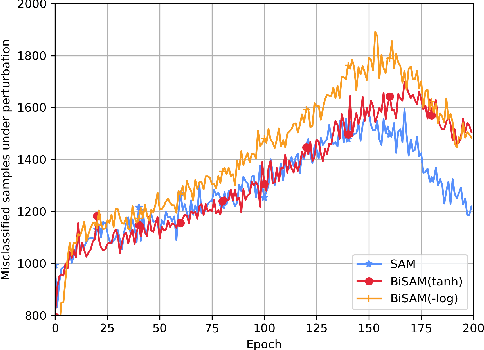
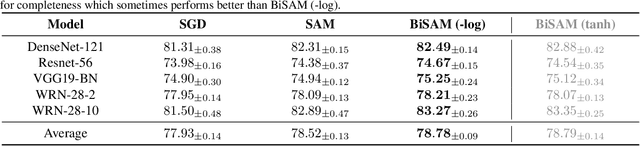
This paper rethinks Sharpness-Aware Minimization (SAM), which is originally formulated as a zero-sum game where the weights of a network and a bounded perturbation try to minimize/maximize, respectively, the same differentiable loss. To fundamentally improve this design, we argue that SAM should instead be reformulated using the 0-1 loss. As a continuous relaxation, we follow the simple conventional approach where the minimizing (maximizing) player uses an upper bound (lower bound) surrogate to the 0-1 loss. This leads to a novel formulation of SAM as a bilevel optimization problem, dubbed as BiSAM. BiSAM with newly designed lower-bound surrogate loss indeed constructs stronger perturbation. Through numerical evidence, we show that BiSAM consistently results in improved performance when compared to the original SAM and variants, while enjoying similar computational complexity. Our code is available at https://github.com/LIONS-EPFL/BiSAM.