 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatially Varying Nanophotonic Neural Networks
Aug 07, 2023



The explosive growth of computation and energy cost of artificial intelligence has spurred strong interests in new computing modalities as potential alternatives to conventional electronic processors. Photonic processors that execute operations using photons instead of electrons, have promised to enable optical neural networks with ultra-low latency and power consumption. However, existing optical neural networks, limited by the underlying network designs, have achieved image recognition accuracy much lower than state-of-the-art electronic neural networks. In this work, we close this gap by introducing a large-kernel spatially-varying convolutional neural network learned via low-dimensional reparameterization techniques. We experimentally instantiate the network with a flat meta-optical system that encompasses an array of nanophotonic structures designed to induce angle-dependent responses. Combined with an extremely lightweight electronic backend with approximately 2K parameters we demonstrate a nanophotonic neural network reaches 73.80\% blind test classification accuracy on CIFAR-10 dataset, and, as such, the first time, an optical neural network outperforms the first modern digital neural network -- AlexNet (72.64\%) with 57M parameters, bringing optical neural network into modern deep learning era.
Stochastic Light Field Holography
Jul 12, 2023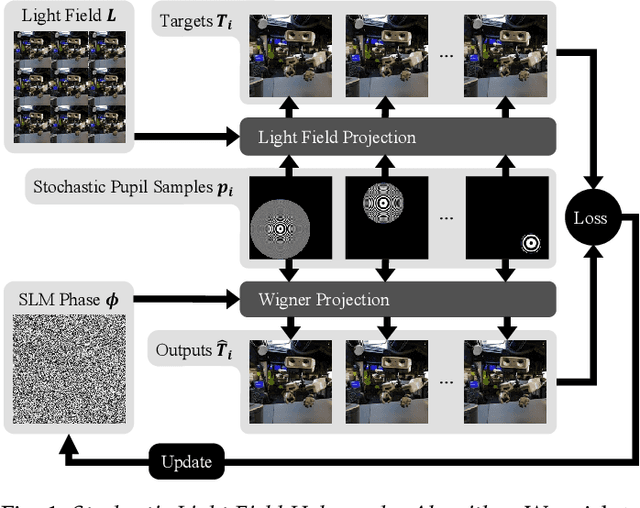


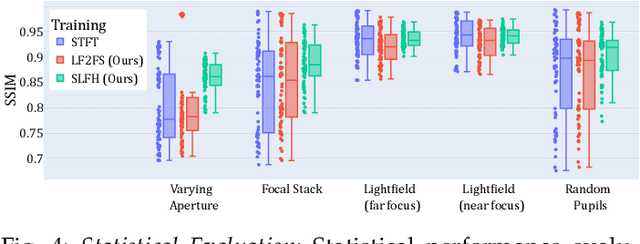
The Visual Turing Test is the ultimate goal to evaluate the realism of holographic displays. Previous studies have focused on addressing challenges such as limited \'etendue and image quality over a large focal volume, but they have not investigated the effect of pupil sampling on the viewing experience in full 3D holograms. In this work, we tackle this problem with a novel hologram generation algorithm motivated by matching the projection operators of incoherent Light Field and coherent Wigner Function light transport. To this end, we supervise hologram computation using synthesized photographs, which are rendered on-the-fly using Light Field refocusing from stochastically sampled pupil states during optimization. The proposed method produces holograms with correct parallax and focus cues, which are important for passing the Visual Turing Test. We validate that our approach compares favorably to state-of-the-art CGH algorithms that use Light Field and Focal Stack supervision. Our experiments demonstrate that our algorithm significantly improves the realism of the viewing experience for a variety of different pupil states.
Neural Étendue Expander for Ultra-Wide-Angle High-Fidelity Holographic Display
Sep 16, 2021
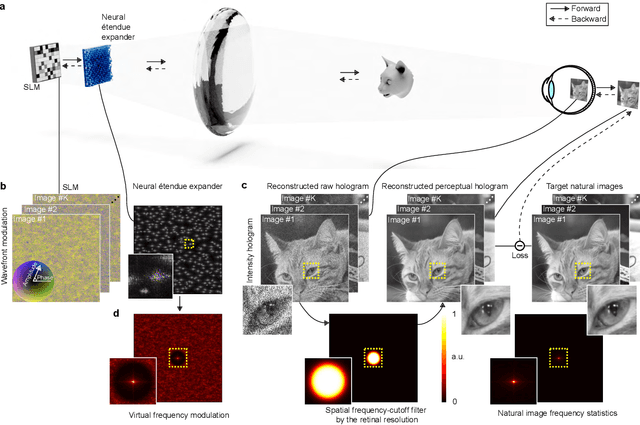


Holographic displays can generate light fields by dynamically modulating the wavefront of a coherent beam of light using a spatial light modulator, promising rich virtual and augmented reality applications. However, the limited spatial resolution of existing dynamic spatial light modulators imposes a tight bound on the diffraction angle. As a result, today's holographic displays possess low \'{e}tendue, which is the product of the display area and the maximum solid angle of diffracted light. The low \'{e}tendue forces a sacrifice of either the field of view (FOV) or the display size. In this work, we lift this limitation by presenting neural \'{e}tendue expanders. This new breed of optical elements, which is learned from a natural image dataset, enables higher diffraction angles for ultra-wide FOV while maintaining both a compact form factor and the fidelity of displayed contents to human viewers. With neural \'{e}tendue expanders, we achieve 64$\times$ \'{e}tendue expansion of natural images with reconstruction quality (measured in PSNR) over 29dB on simulated retinal-resolution images. As a result, the proposed approach with expansion factor 64$\times$ enables high-fidelity ultra-wide-angle holographic projection of natural images using an 8K-pixel SLM, resulting in a 18.5 mm eyebox size and 2.18 steradians FOV, covering 85\% of the human stereo FOV.
ZeroScatter: Domain Transfer for Long Distance Imaging and Vision through Scattering Media
Feb 11, 2021


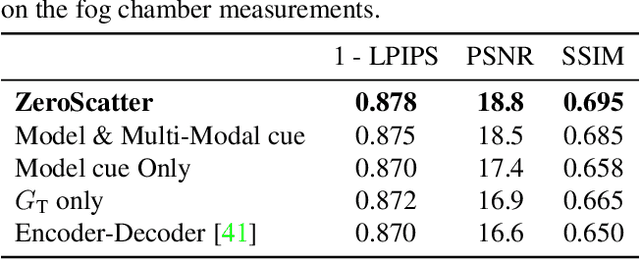
Adverse weather conditions, including snow, rain, and fog pose a challenge for both human and computer vision in outdoor scenarios. Handling these environmental conditions is essential for safe decision making, especially in autonomous vehicles, robotics, and drones. Most of today's supervised imaging and vision approaches, however, rely on training data collected in the real world that is biased towards good weather conditions, with dense fog, snow, and heavy rain as outliers in these datasets. Without training data, let alone paired data, existing autonomous vehicles often limit themselves to good conditions and stop when dense fog or snow is detected. In this work, we tackle the lack of supervised training data by combining synthetic and indirect supervision. We present ZeroScatter, a domain transfer method for converting RGB-only captures taken in adverse weather into clear daytime scenes. ZeroScatter exploits model-based, temporal, multi-view, multi-modal, and adversarial cues in a joint fashion, allowing us to train on unpaired, biased data. We assess the proposed method using real-world captures, and the proposed method outperforms existing monocular de-scattering approaches by 2.8 dB PSNR on controlled fog chamber measurements.
Gated3D: Monocular 3D Object Detection From Temporal Illumination Cues
Feb 06, 2021
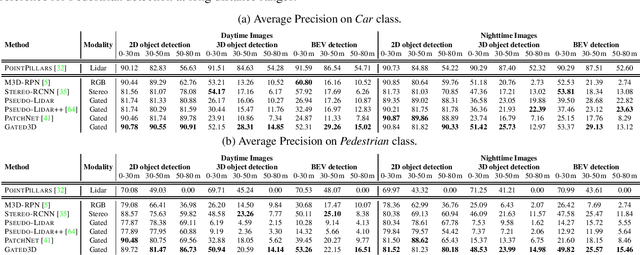
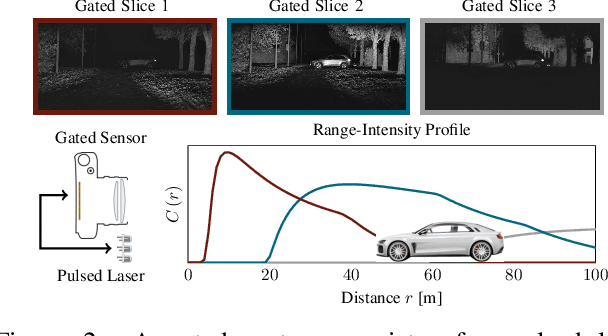
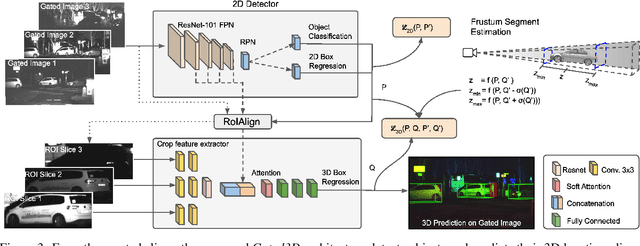
Today's state-of-the-art methods for 3D object detection are based on lidar, stereo, or monocular cameras. Lidar-based methods achieve the best accuracy, but have a large footprint, high cost, and mechanically-limited angular sampling rates, resulting in low spatial resolution at long ranges. Recent approaches based on low-cost monocular or stereo cameras promise to overcome these limitations but struggle in low-light or low-contrast regions as they rely on passive CMOS sensors. In this work, we propose a novel 3D object detection modality that exploits temporal illumination cues from a low-cost monocular gated imager. We propose a novel deep detector architecture, Gated3D, that is tailored to temporal illumination cues from three gated images. Gated images allow us to exploit mature 2D object feature extractors that guide the 3D predictions through a frustum segment estimation. We assess the proposed method on a novel 3D detection dataset that includes gated imagery captured in over 10,000 km of driving data. We validate that our method outperforms state-of-the-art monocular and stereo approaches at long distances. We will release our code and dataset, opening up a new sensor modality as an avenue to replace lidar in autonomous driving.
Automated Detection of Left Ventricle in Arterial Input Function Images for Inline Perfusion Mapping using Deep Learning: A study of 15,000 Patients
Oct 16, 2019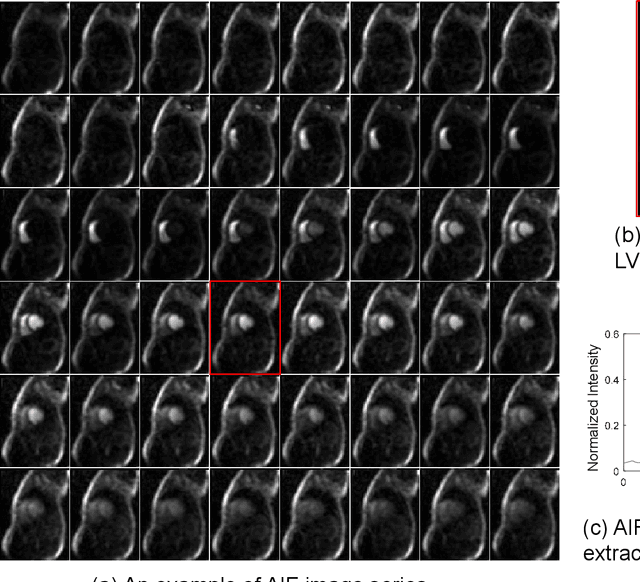
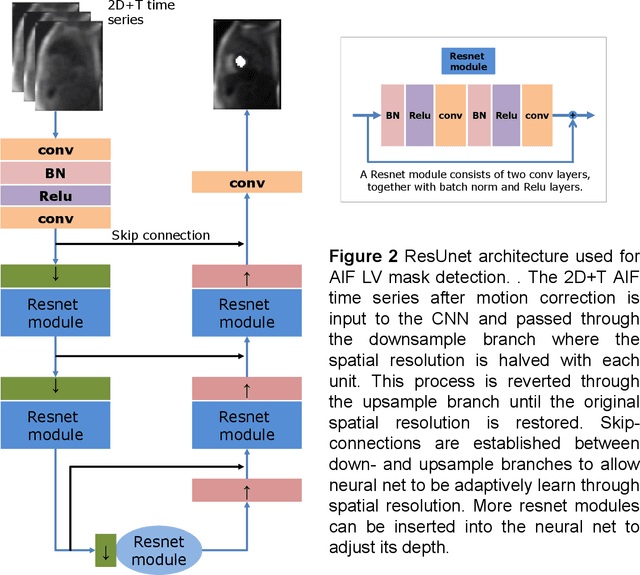
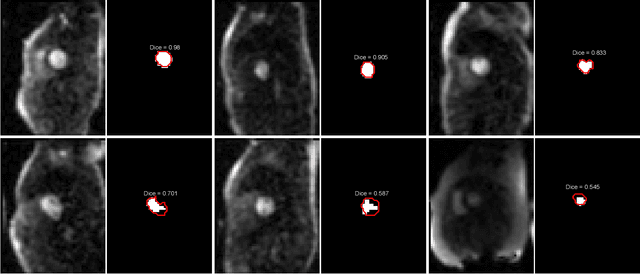
Quantification of myocardial perfusion has the potential to improve detection of regional and global flow reduction. Significant effort has been made to automate the workflow, where one essential step is the arterial input function (AIF) extraction. Since failure here invalidates quantification, high accuracy is required. For this purpose, this study presents a robust AIF detection method using the convolutional neural net (CNN) model. CNN models were trained by assembling 25,027 scans (N=12,984 patients) from three hospitals, seven scanners. A test set of 5,721 scans (N=2,805 patients) evaluated model performance. The 2D+T AIF time series was inputted into CNN. Two variations were investigated: a) Two Classes (2CS) for background and foreground (LV mask); b) Three Classes (3CS) for background, foreground LV and RV. Final model was deployed on MR scanners via the Gadgetron InlineAI. Model loading time on MR scanner was ~340ms and applying it took ~180ms. The 3CS model successfully detect LV for 99.98% of all test cases (1 failed out of 5,721 cases). The mean Dice ratio for 3CS was 0.87+/-0.08 with 92.0% of all test cases having Dice ratio >0.75, while the 2CS model gave lower Dice of 0.82+/-0.22 (P<1e-5). Extracted AIF signals using CNN were further compared to manual ground-truth for foot-time, peak-time, first-pass duration, peak value and area-under-curve. No significant differences were found for all features (P>0.2). This study proposed, validated, and deployed a robust CNN solution to detect the LV for the extraction of the AIF signal used in fully automated perfusion flow mapping. A very large data cohort was assembled and resulting models were deployed to MR scanners for fully inline AI in clinical hospitals.