 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGated2Gated: Self-Supervised Depth Estimation from Gated Images
Dec 04, 2021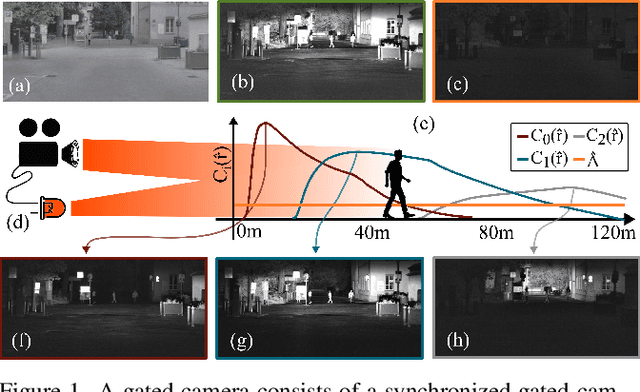
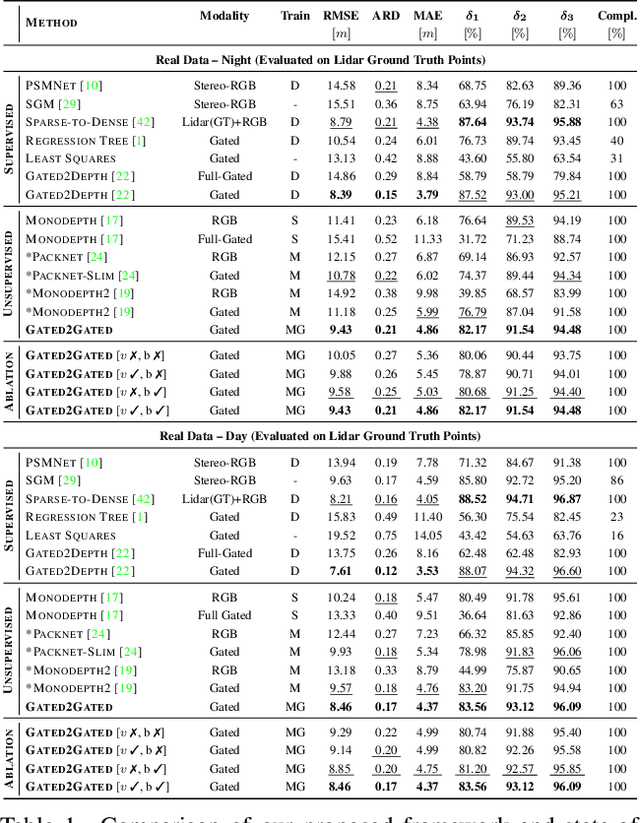
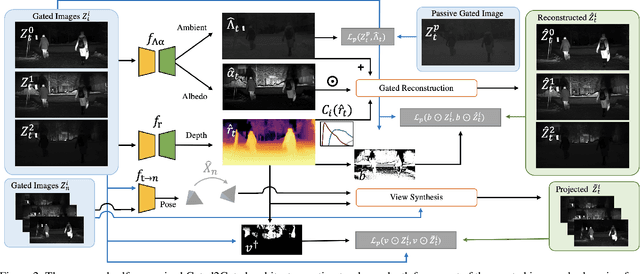
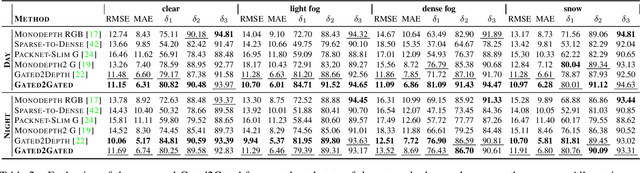
Gated cameras hold promise as an alternative to scanning LiDAR sensors with high-resolution 3D depth that is robust to back-scatter in fog, snow, and rain. Instead of sequentially scanning a scene and directly recording depth via the photon time-of-flight, as in pulsed LiDAR sensors, gated imagers encode depth in the relative intensity of a handful of gated slices, captured at megapixel resolution. Although existing methods have shown that it is possible to decode high-resolution depth from such measurements, these methods require synchronized and calibrated LiDAR to supervise the gated depth decoder -- prohibiting fast adoption across geographies, training on large unpaired datasets, and exploring alternative applications outside of automotive use cases. In this work, we fill this gap and propose an entirely self-supervised depth estimation method that uses gated intensity profiles and temporal consistency as a training signal. The proposed model is trained end-to-end from gated video sequences, does not require LiDAR or RGB data, and learns to estimate absolute depth values. We take gated slices as input and disentangle the estimation of the scene albedo, depth, and ambient light, which are then used to learn to reconstruct the input slices through a cyclic loss. We rely on temporal consistency between a given frame and neighboring gated slices to estimate depth in regions with shadows and reflections. We experimentally validate that the proposed approach outperforms existing supervised and self-supervised depth estimation methods based on monocular RGB and stereo images, as well as supervised methods based on gated images.
Gated3D: Monocular 3D Object Detection From Temporal Illumination Cues
Feb 06, 2021
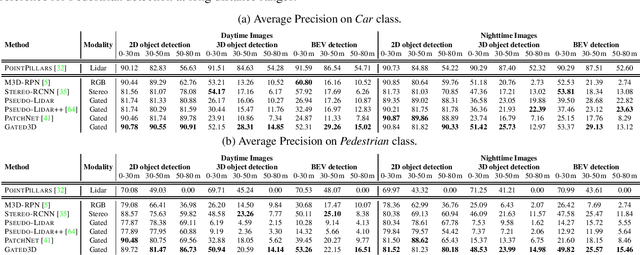
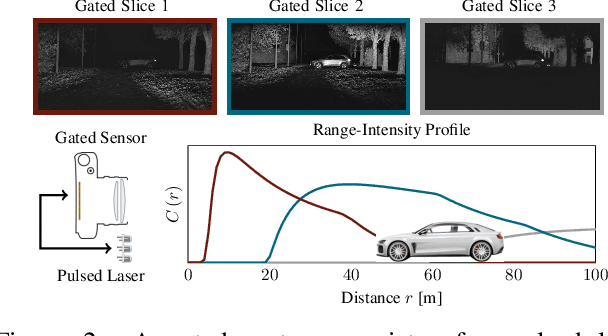
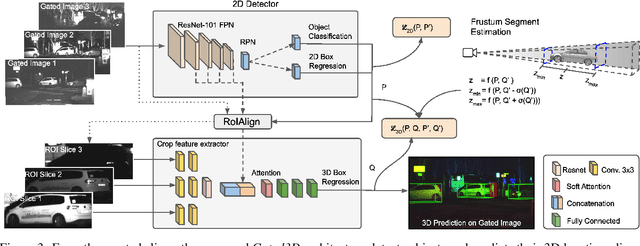
Today's state-of-the-art methods for 3D object detection are based on lidar, stereo, or monocular cameras. Lidar-based methods achieve the best accuracy, but have a large footprint, high cost, and mechanically-limited angular sampling rates, resulting in low spatial resolution at long ranges. Recent approaches based on low-cost monocular or stereo cameras promise to overcome these limitations but struggle in low-light or low-contrast regions as they rely on passive CMOS sensors. In this work, we propose a novel 3D object detection modality that exploits temporal illumination cues from a low-cost monocular gated imager. We propose a novel deep detector architecture, Gated3D, that is tailored to temporal illumination cues from three gated images. Gated images allow us to exploit mature 2D object feature extractors that guide the 3D predictions through a frustum segment estimation. We assess the proposed method on a novel 3D detection dataset that includes gated imagery captured in over 10,000 km of driving data. We validate that our method outperforms state-of-the-art monocular and stereo approaches at long distances. We will release our code and dataset, opening up a new sensor modality as an avenue to replace lidar in autonomous driving.
Gated2Depth: Real-time Dense Lidar from Gated Images
Feb 13, 2019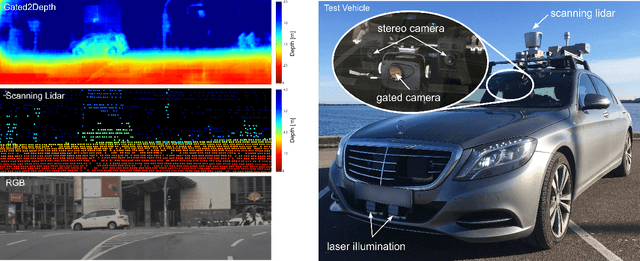
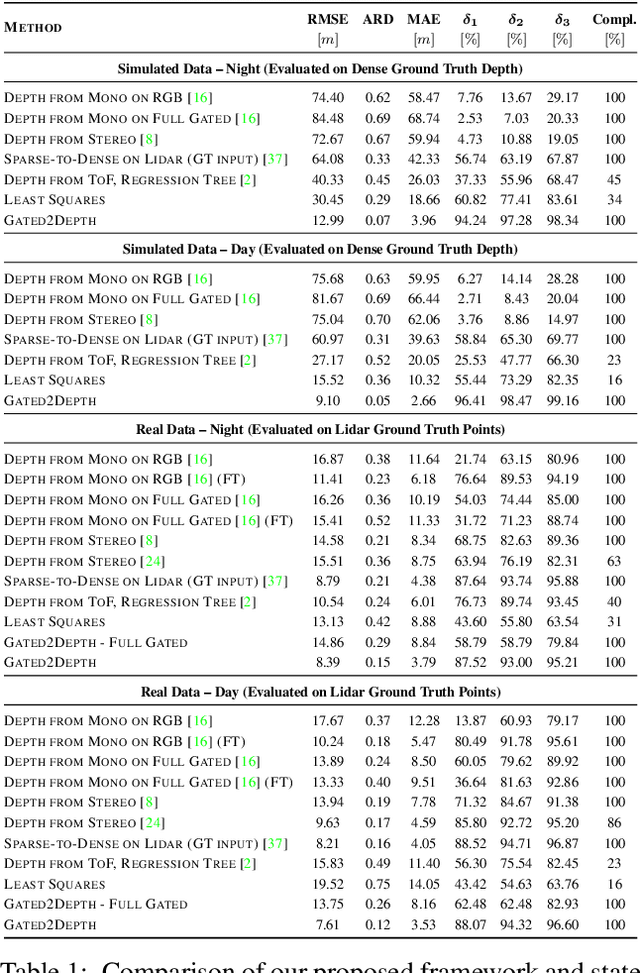

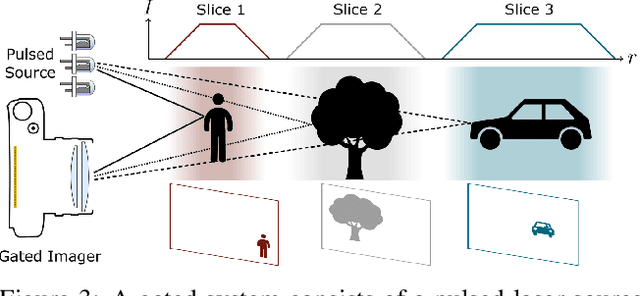
We present an imaging framework which converts three images from a gated camera into high-resolution depth maps with depth resolution comparable to pulsed lidar measurements. Existing scanning lidar systems achieve low spatial resolution at large ranges due to mechanically-limited angular sampling rates, restricting scene understanding tasks to close-range clusters with dense sampling. In addition, today's lidar detector technologies, short-pulsed laser sources and scanning mechanics result in high cost, power consumption and large form-factors. We depart from point scanning and propose a learned architecture that recovers high-fidelity dense depth from three temporally gated images, acquired with a flash source and a high-resolution CMOS sensor. The proposed architecture exploits semantic context across gated slices, and is trained on a synthetic discriminator loss without the need of dense depth labels. The method is real-time and essentially turns a gated camera into a low-cost dense flash lidar which we validate on a wide range of outdoor driving captures and in simulations.
A General Framework for the Recognition of Online Handwritten Graphics
Sep 19, 2017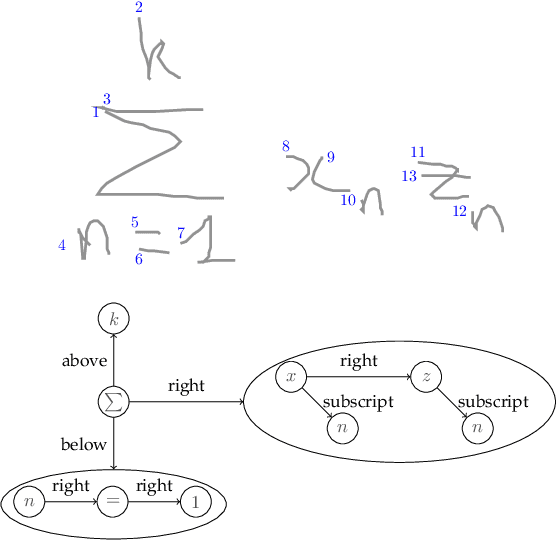
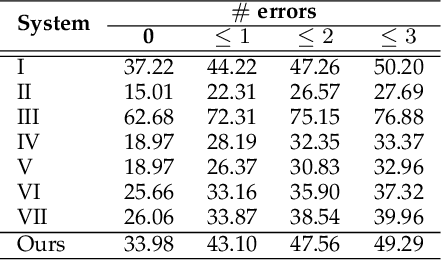
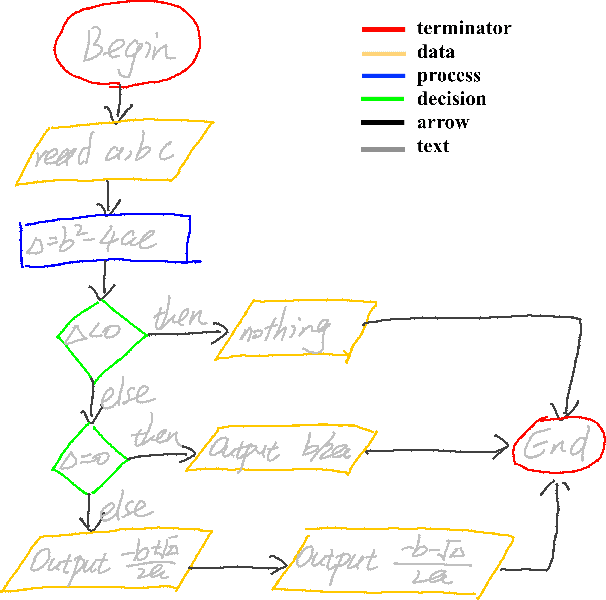
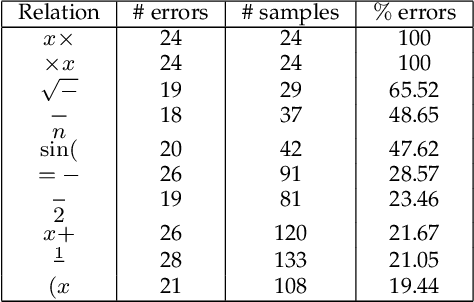
We propose a new framework for the recognition of online handwritten graphics. Three main features of the framework are its ability to treat symbol and structural level information in an integrated way, its flexibility with respect to different families of graphics, and means to control the tradeoff between recognition effectiveness and computational cost. We model a graphic as a labeled graph generated from a graph grammar. Non-terminal vertices represent subcomponents, terminal vertices represent symbols, and edges represent relations between subcomponents or symbols. We then model the recognition problem as a graph parsing problem: given an input stroke set, we search for a parse tree that represents the best interpretation of the input. Our graph parsing algorithm generates multiple interpretations (consistent with the grammar) and then we extract an optimal interpretation according to a cost function that takes into consideration the likelihood scores of symbols and structures. The parsing algorithm consists in recursively partitioning the stroke set according to structures defined in the grammar and it does not impose constraints present in some previous works (e.g. stroke ordering). By avoiding such constraints and thanks to the powerful representativeness of graphs, our approach can be adapted to the recognition of different graphic notations. We show applications to the recognition of mathematical expressions and flowcharts. Experimentation shows that our method obtains state-of-the-art accuracy in both applications.