 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowing the Distance: Understanding the Gap Between Synthetic and Real Data For Face Parsing
Mar 27, 2023
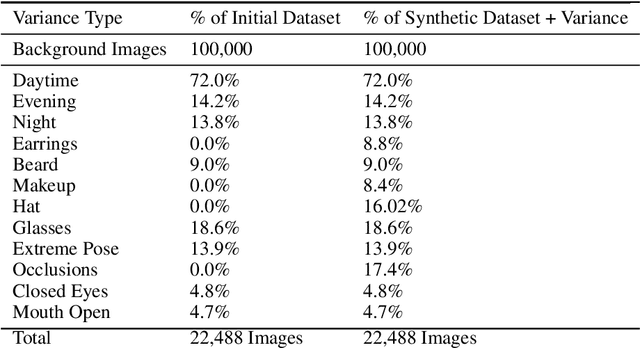

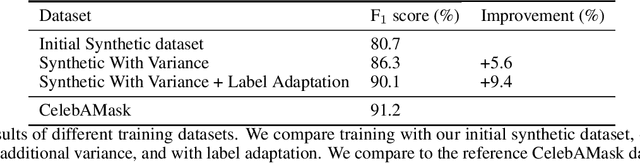
The use of synthetic data for training computer vision algorithms has become increasingly popular due to its cost-effectiveness, scalability, and ability to provide accurate multi-modality labels. Although recent studies have demonstrated impressive results when training networks solely on synthetic data, there remains a performance gap between synthetic and real data that is commonly attributed to lack of photorealism. The aim of this study is to investigate the gap in greater detail for the face parsing task. We differentiate between three types of gaps: distribution gap, label gap, and photorealism gap. Our findings show that the distribution gap is the largest contributor to the performance gap, accounting for over 50% of the gap. By addressing this gap and accounting for the labels gap, we demonstrate that a model trained on synthetic data achieves comparable results to one trained on a similar amount of real data. This suggests that synthetic data is a viable alternative to real data, especially when real data is limited or difficult to obtain. Our study highlights the importance of content diversity in synthetic datasets and challenges the notion that the photorealism gap is the most critical factor affecting the performance of computer vision models trained on synthetic data.
Hands-Up: Leveraging Synthetic Data for Hands-On-Wheel Detection
May 31, 2022
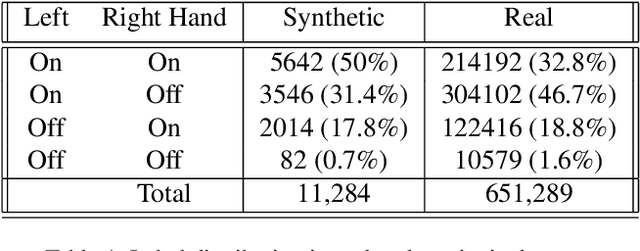

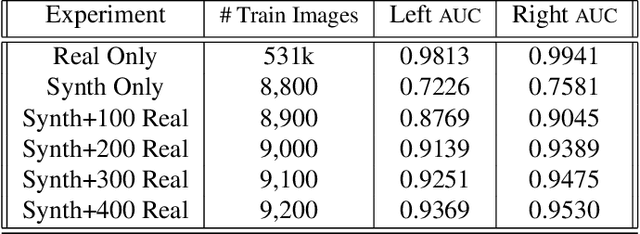
Over the past few years there has been major progress in the field of synthetic data generation using simulation based techniques. These methods use high-end graphics engines and physics-based ray-tracing rendering in order to represent the world in 3D and create highly realistic images. Datagen has specialized in the generation of high-quality 3D humans, realistic 3D environments and generation of realistic human motion. This technology has been developed into a data generation platform which we used for these experiments. This work demonstrates the use of synthetic photo-realistic in-cabin data to train a Driver Monitoring System that uses a lightweight neural network to detect whether the driver's hands are on the wheel. We demonstrate that when only a small amount of real data is available, synthetic data can be a simple way to boost performance. Moreover, we adopt the data-centric approach and show how performing error analysis and generating the missing edge-cases in our platform boosts performance. This showcases the ability of human-centric synthetic data to generalize well to the real world, and help train algorithms in computer vision settings where data from the target domain is scarce or hard to collect.
Generalizing Across Multi-Objective Reward Functions in Deep Reinforcement Learning
Sep 17, 2018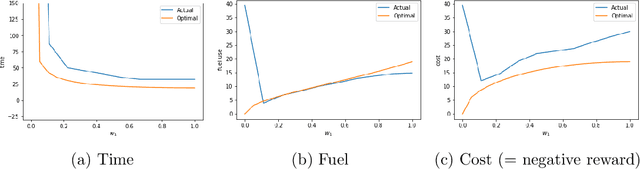
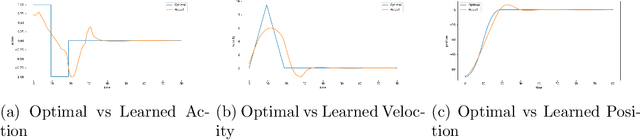
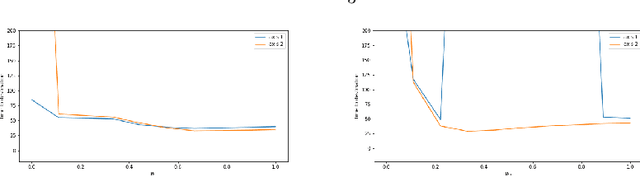
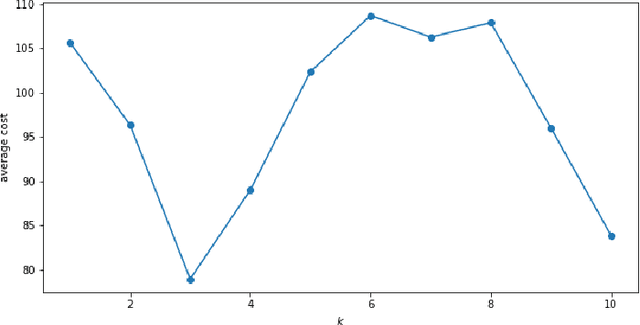
Many reinforcement-learning researchers treat the reward function as a part of the environment, meaning that the agent can only know the reward of a state if it encounters that state in a trial run. However, we argue that this is an unnecessary limitation and instead, the reward function should be provided to the learning algorithm. The advantage is that the algorithm can then use the reward function to check the reward for states that the agent hasn't even encountered yet. In addition, the algorithm can simultaneously learn policies for multiple reward functions. For each state, the algorithm would calculate the reward using each of the reward functions and add the rewards to its experience replay dataset. The Hindsight Experience Replay algorithm developed by Andrychowicz et al. (2017) does just this, and learns to generalize across a distribution of sparse, goal-based rewards. We extend this algorithm to linearly-weighted, multi-objective rewards and learn a single policy that can generalize across all linear combinations of the multi-objective reward. Whereas other multi-objective algorithms teach the Q-function to generalize across the reward weights, our algorithm enables the policy to generalize, and can thus be used with continuous actions.