 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHands-Up: Leveraging Synthetic Data for Hands-On-Wheel Detection
May 31, 2022
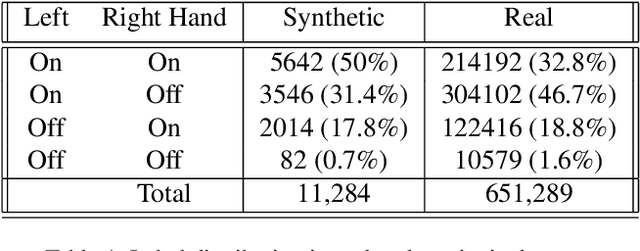

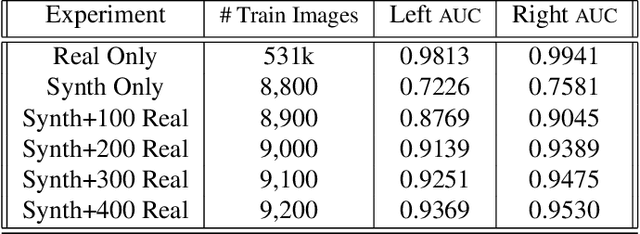
Over the past few years there has been major progress in the field of synthetic data generation using simulation based techniques. These methods use high-end graphics engines and physics-based ray-tracing rendering in order to represent the world in 3D and create highly realistic images. Datagen has specialized in the generation of high-quality 3D humans, realistic 3D environments and generation of realistic human motion. This technology has been developed into a data generation platform which we used for these experiments. This work demonstrates the use of synthetic photo-realistic in-cabin data to train a Driver Monitoring System that uses a lightweight neural network to detect whether the driver's hands are on the wheel. We demonstrate that when only a small amount of real data is available, synthetic data can be a simple way to boost performance. Moreover, we adopt the data-centric approach and show how performing error analysis and generating the missing edge-cases in our platform boosts performance. This showcases the ability of human-centric synthetic data to generalize well to the real world, and help train algorithms in computer vision settings where data from the target domain is scarce or hard to collect.
Using Synthetic Images To Uncover Population Biases In Facial Landmarks Detection
Nov 01, 2021
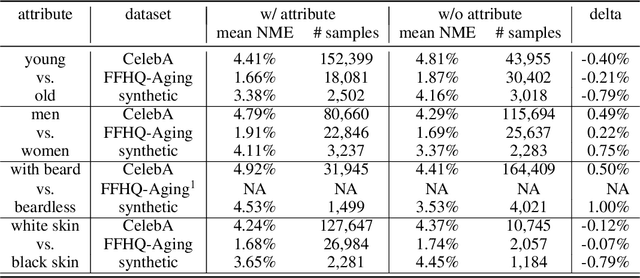
In order to analyze a trained model performance and identify its weak spots, one has to set aside a portion of the data for testing. The test set has to be large enough to detect statistically significant biases with respect to all the relevant sub-groups in the target population. This requirement may be difficult to satisfy, especially in data-hungry applications. We propose to overcome this difficulty by generating synthetic test set. We use the face landmarks detection task to validate our proposal by showing that all the biases observed on real datasets are also seen on a carefully designed synthetic dataset. This shows that synthetic test sets can efficiently detect a model's weak spots and overcome limitations of real test set in terms of quantity and/or diversity.
EXPO-HD: Exact Object Perception usingHigh Distraction Synthetic Data
Jul 28, 2020



We present a new labeled visual dataset intended for use in object detection and segmentation tasks. This dataset consists of 5,000 synthetic photorealistic images with their corresponding pixel-perfect segmentation ground truth. The goal is to create a photorealistic 3D representation of a specific object and utilize it within a simulated training data setting to achieve high accuracy on manually gathered and annotated real-world data. Expo Markers were chosen for this task, fitting our requirements of an exact object due to the exact texture, size and 3D shape. An additional advantage is the availability of this object in offices around the world for easy testing and validation of our results. We generate the data using a domain randomization technique that also simulates other photorealistic objects in the scene, known as distraction objects. These objects provide visual complexity, occlusions, and lighting challenges to help our model gain robustness in training. We are also releasing our manually-labeled real-image test dataset. This white-paper provides strong evidence that photorealistic simulated data can be used in practical real world applications as a more scalable and flexible solution than manually-captured data. https://github.com/DataGenResearchTeam/expo_markers