 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Synthetic Images To Uncover Population Biases In Facial Landmarks Detection
Nov 01, 2021
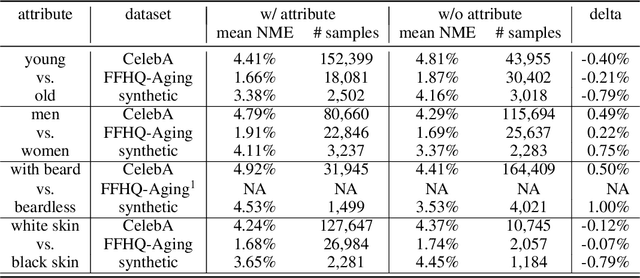
In order to analyze a trained model performance and identify its weak spots, one has to set aside a portion of the data for testing. The test set has to be large enough to detect statistically significant biases with respect to all the relevant sub-groups in the target population. This requirement may be difficult to satisfy, especially in data-hungry applications. We propose to overcome this difficulty by generating synthetic test set. We use the face landmarks detection task to validate our proposal by showing that all the biases observed on real datasets are also seen on a carefully designed synthetic dataset. This shows that synthetic test sets can efficiently detect a model's weak spots and overcome limitations of real test set in terms of quantity and/or diversity.
TextRay: Mining Clinical Reports to Gain a Broad Understanding of Chest X-rays
Jun 06, 2018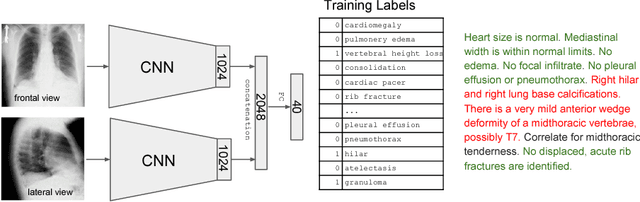
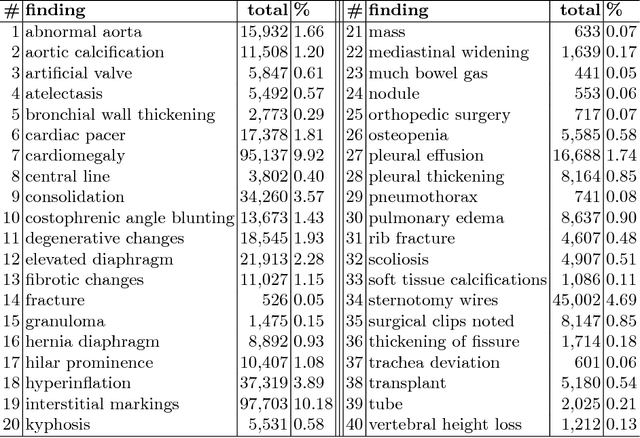
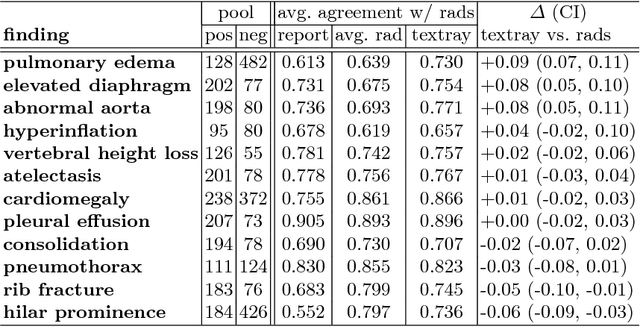
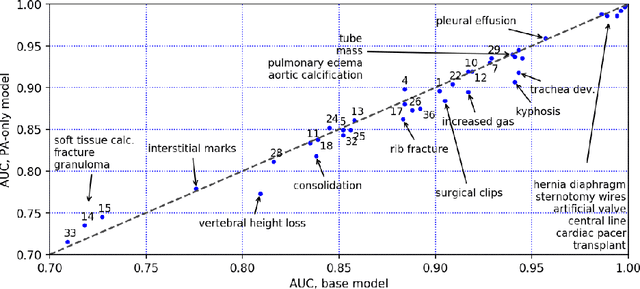
The chest X-ray (CXR) is by far the most commonly performed radiological examination for screening and diagnosis of many cardiac and pulmonary diseases. There is an immense world-wide shortage of physicians capable of providing rapid and accurate interpretation of this study. A radiologist-driven analysis of over two million CXR reports generated an ontology including the 40 most prevalent pathologies on CXR. By manually tagging a relatively small set of sentences, we were able to construct a training set of 959k studies. A deep learning model was trained to predict the findings given the patient frontal and lateral scans. For 12 of the findings we compare the model performance against a team of radiologists and show that in most cases the radiologists agree on average more with the algorithm than with each other.